实验简介
编写一个通用高速缓存模拟器,并优化小型矩阵转置核心函数,以最小化对模拟高速缓存的不命中次数。
预备知识
1. 局部性原理
局部性通常有两种形式:
- 时间局部性:被引用过一次的内存位置很可能在不远的将来被多次引用。
- 空间局部性:如一个内存位置被引用,其附近的内存位置很可能在不远的将来被引用。
2. 存储器层次结构
下图展示了一个典型的存储器层次结构:
![]()
可以看出,从高往低走,存储设备变得更慢,更大,更便宜。
3. 缓存
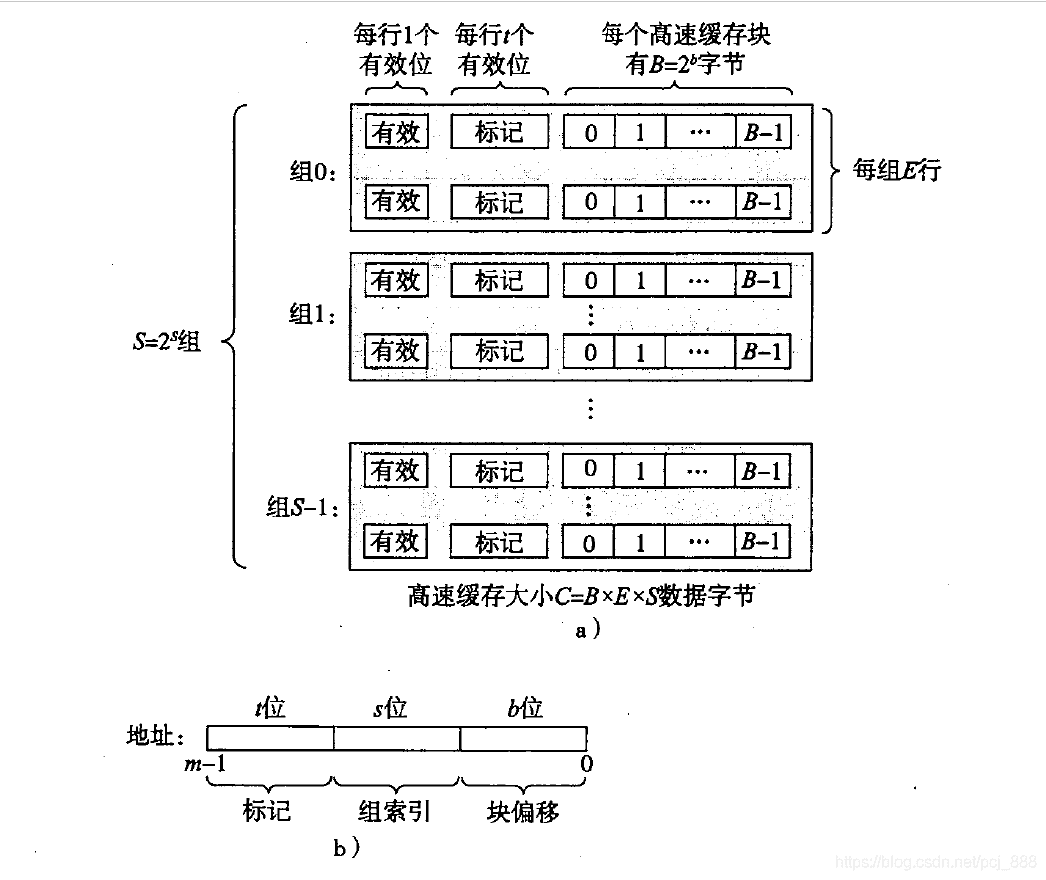
缓存被组织成一个有S组,每组E行,每行由一个B字节数据块、一个有效位、一个标记位组成。结构如下:
![]()
一个m位地址被划分为标记、组索引、块偏移三个部分。
缓存确定一个请求是否命中,然后抽取被请求字的过程分为三步:
- 组选择:从地址中间抽取s位组索引,得到组号i。比如s=4, 组索引为0010时,组号i = 2。
- 行匹配:从地址抽取t位标记,与组i中每个行的标记进行比较,如标记相等且有效位为1则命中。
- 字抽取:根据地址的b位块偏移, 直接从行中得到数据。
实验准备
从CSAPP官网获取实验文件。
阅读cachelab.pdf,了解实验内容。
实验一: 实现缓存模拟器
修改csim.c, 实现LRU策略的缓存模拟器,最终目标是与csim-ref执行结果一致。
实现要点:
使用getopt解析命令行参数,man 3 getopt查看用法。
解析traces文件,可以使用fgets和sscanf实现。
缓存结构本质是一个二维数组 cache[S][E],但由于s, E, b不确定, 需要使用malloc分配。
缓存替换策略采用LRU,可通过每行设计一个时间戳,每更新一次缓存将时间戳加1。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
|
struct Args {
int s;
int E;
int b;
char traceFile[BUFFER_SIZE];
};
void parseArgs(int argc, char **argv, struct Args *args)
{
int opt;
while ((opt = getopt(argc, argv, "hvs:E:b:t:")) != -1) {
if (opt == 'h') {
printHelp();
} else if (opt == 's') {
args->s = atoi(optarg);
} else if (opt == 'E') {
args->E = atoi(optarg);
} else if (opt == 'b') {
args->b = atoi(optarg);
} else if (opt == 't') {
strcpy(args->traceFile, optarg);
} else {
;
}
}
}
void initCache(struct Cache *cache, struct Args *args) {
cache->s = args->s;
cache->S = 1 << cache->s;
cache->E = args->E;
cache->b = args->b;
cache->sets = (struct CacheSet *)malloc(sizeof(struct CacheSet) * cache->S);
for(int i = 0; i < cache->S; ++i) {
cache->sets[i].lines = (struct CacheLine *)malloc(sizeof(struct CacheLine) * cache->E);
for(int j = 0; j < cache->E; ++j) {
cache->sets[i].lines[j].valid = INVALID;
cache->sets[i].lines[j].tag = INVALID_TAG;
}
}
}
void recycleCache(struct Cache *cache) {
for(int i = 0; i < cache->S; ++i) {
free(cache->sets[i].lines);
}
free(cache->sets);
}
void updateTimeStamp(struct Cache *cache) {
int numSets = cache->S;
int numLines = cache->E;
for(int i = 0; i < numSets; ++i) {
for(int j = 0; j < numLines; ++j) {
if(cache->sets[i].lines[j].valid == VALID) {
++cache->sets[i].lines[j].timestamp;
}
}
}
}
void update(struct Cache *cache, int64_t addr, struct Result *result) {
int numLines = cache->E;
int setIndex = (addr >> cache->b) & (cache->S - 1);
int tag = addr >> (cache->s + cache->b);
struct CacheSet *curSet = &cache->sets[setIndex];
for(int i = 0; i < numLines; ++i) {
if(curSet->lines[i].tag == tag) {
++result->hits;
curSet->lines[i].timestamp = 0;
return;
}
}
++result->misses;
for(int i = 0; i < numLines; ++i) {
if(curSet->lines[i].valid == INVALID) {
curSet->lines[i].tag = tag;
curSet->lines[i].valid = VALID;
curSet->lines[i].timestamp = 0;
return;
}
}
++result->evictions;
int maxIdx = 0;
int maxTime = curSet->lines[0].timestamp;
for(int i = 1; i < numLines; ++i) {
if(curSet->lines[i].timestamp > maxTime) {
maxTime = curSet->lines[i].timestamp;
maxIdx = i;
}
}
curSet->lines[maxIdx].tag = tag;
curSet->lines[maxIdx].timestamp = 0;
}
void updateCache(struct Cache *cache, char ch, int64_t addr, struct Result *result)
{
update(cache, addr, result);
if(ch == 'M') {
update(cache, addr, result);
}
updateTimeStamp(cache);
}
void DoParse(struct Cache *cache, char *traceFile, struct Result *result) {
FILE *fp;
char ch;
int size;
int64_t addr;
char buf[BUFFER_SIZE];
fp = fopen(traceFile, "r");
if(fp == NULL) {
printf("open traceFile: %s failed!\n", traceFile);
return;
}
while(fgets(buf, BUFFER_SIZE, fp) != NULL) {
if(buf[0] == 'I') {
continue;
}
sscanf(buf, " %c %lx,%d\n", &ch, &addr, &size);
updateCache(cache, ch, addr, result);
}
fclose(fp);
}
int main(int argc, char **argv)
{
struct Args args;
struct Cache cache;
struct Result res = {0, 0, 0};
parseArgs(argc, argv, &args);
initCache(&cache, &args);
DoParse(&cache, args.traceFile, &res);
recycleCache(&cache);
printSummary(res.hits, res.misses, res.evictions);
return 0;
}
|
实验二: 优化矩阵转置
实验二要求在trans.c中实现矩阵转置函数,最小化缓存不命中的次数。
实验二中的缓存结构为 S = 5, E = 1, b = 5,即32组,每组1行,每行32字节,每行可放8个int数
利用分块技术和局部变量减少miss,分块技术可参考 waside-blocking.pdf
32 * 32
由于缓存的每一行能放8个数,考虑将32 * 32划分为16个8 * 8 的分块,每次处理单个8 * 8的分块,再利用局部变量减少miss。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| void transpose_submit(int M, int N, int A[N][M], int B[M][N])
{
int a1, a2, a3, a4, a5, a6, a7, a8;
for(int i = 0; i < M; i += 8) {
for(int j = 0; j < N; j += 8) {
for(int k = i; k < i + 8; ++k) {
a1 = A[k][j];
a2 = A[k][j+1];
a3 = A[k][j+2];
a4 = A[k][j+3];
a5 = A[k][j+4];
a6 = A[k][j+5];
a7 = A[k][j+6];
a8 = A[k][j+7];
B[j][k] = a1;
B[j+1][k] = a2;
B[j+2][k] = a3;
B[j+3][k] = a4;
B[j+4][k] = a5;
B[j+5][k] = a6;
B[j+6][k] = a7;
B[j+7][k] = a8;
}
}
}
}
|
如果改用4 * 4分块,会导致缓存利用不足,因为缓存的一行可以放8个数;也不能用16 * 16分块,会导致块内冲突。
使用8个局部变量(a1 ~ a8)的目的是避免写入B时,在对角线发生冲突不命中。因为A和B中相同位置的元素会映射到同一行。而矩阵转置不会改变对角线上的元素位置,导致多出现两次不命中。
61 * 67
和32*32类似,尝试分块法,发现8 * 8即可满足要求,再利用局部变量减少miss。
首先对56 * 64部分进行8 * 8分块,其余部分直接简单转置即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| void transpose_submit(int M, int N, int A[N][M], int B[M][N])
{
int i, j, a1, a2, a3, a4, a5, a6, a7, a8;
for(j = 0; j < 56; j += 8) {
for(i = 0; i < 64; ++i) {
a1 = A[i][j];
a2 = A[i][j+1];
a3 = A[i][j+2];
a4 = A[i][j+3];
a5 = A[i][j+4];
a6 = A[i][j+5];
a7 = A[i][j+6];
a8 = A[i][j+7];
B[j][i] = a1;
B[j+1][i] = a2;
B[j+2][i] = a3;
B[j+3][i] = a4;
B[j+4][i] = a5;
B[j+5][i] = a6;
B[j+6][i] = a7;
B[j+7][i] = a8;
}
}
for(i = 0; i < 64; ++i) {
for(j = 56; j < 61; ++j) {
a1 = A[i][j];
B[j][i] = a1;
}
}
for(i = 64; i < 67; ++i) {
for(j = 0; j < 61; ++j) {
a1 = A[i][j];
B[j][i] = a1;
}
}
}
|
64 * 64
对于64 * 64矩阵,每4行就有冲突,如使用8 * 8分块会导致块内就有冲突,只能得0分。
因此,这里改用4 * 4分块,再利用局部变量,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
void transpose_submit(int M, int N, int A[N][M], int B[M][N])
{
int i, j, l;
int a1, a2, a3, a4, a5, a6, a7, a8;
for(i = 0; i < M; i += 4) {
for(j = 0; j < N; j += 4) {
for(l = i; l < i + 4; l += 2) {
a1 = A[l][j];
a2 = A[l][j+1];
a3 = A[l][j+2];
a4 = A[l][j+3];
a5 = A[l+1][j];
a6 = A[l+1][j+1];
a7 = A[l+1][j+2];
a8 = A[l+1][j+3];
B[j][l] = a1;
B[j+1][l] = a2;
B[j+2][l] = a3;
B[j+3][l] = a4;
B[j][l+1] = a5;
B[j+1][l+1] = a6;
B[j+2][l+1] = a7;
B[j+3][l+1] = a8;
}
}
}
}
|
结果为1667次,没有满分,原因是没有充分利用缓存。需要满分的可以参考:https://www.cnblogs.com/liqiuhao/p/8026100.html?utm_source=debugrun&utm_medium=referral
实验结果
代码上传到github,仅供参考:https://github.com/PCJ600/CacheLab
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| # ./driver.py
Part A: Testing cache simulator
Running ./test-csim
Your simulator Reference simulator
Points (s,E,b) Hits Misses Evicts Hits Misses Evicts
3 (1,1,1) 9 8 6 9 8 6 traces/yi2.trace
3 (4,2,4) 4 5 2 4 5 2 traces/yi.trace
3 (2,1,4) 2 3 1 2 3 1 traces/dave.trace
3 (2,1,3) 167 71 67 167 71 67 traces/trans.trace
3 (2,2,3) 201 37 29 201 37 29 traces/trans.trace
3 (2,4,3) 212 26 10 212 26 10 traces/trans.trace
3 (5,1,5) 231 7 0 231 7 0 traces/trans.trace
6 (5,1,5) 265189 21775 21743 265189 21775 21743 traces/long.trace
27
Part B: Testing transpose function
Running ./test-trans -M 32 -N 32
Running ./test-trans -M 64 -N 64
Running ./test-trans -M 61 -N 67
Cache Lab summary:
Points Max pts Misses
Csim correctness 27.0 27
Trans perf 32x32 8.0 8 287
Trans perf 64x64 3.8 8 1667
Trans perf 61x67 10.0 10 1889
Total points 48.8 53
|
参考资料
《深入理解计算机系统 原书第3版》
CSAPP实验之cacheLab