前言
Redis没有直接使用基础数据结构来实现数据库,而是基于这些数据结构创建了一个对象系统。这个系统包含字符串对象、列表对象、哈希对象、集合对象、有序集合对象。
1. Redis3.0中的6种基础数据结构
| 数据结构 | 应用场景 |
|---|---|
| 简单动态字符串 | 保存字符串值 |
| 链表 | 列表键,发布与订阅,慢查询,监视器 |
| 字典 | 哈希键,数据库键空间 |
| 跳跃表 | 有序集合键 |
| 整数集合 | 集合键 |
| 压缩列表 | 列表键、哈希键 |
2. 对象的类型和编码
Redis使用对象表示数据库中的键和值,每次在Redis新建一个键值对都会创建两个对象,键对象和值对象。
Redis中的每个对象由一个struct redisObject结构表示:
1 | // src/redis.h |
其中type属性表示对象类型, encoding属性表示对象编码。以下介绍对象类型和对象编码的概念。
2.1 对象类型
Redis 3.0中,定义如下5种对象类型:
| 类型常量 | 对象名称 | TYPE命令的输出 |
|---|---|---|
| REDIS_STRING | 字符串 | “string” |
| REDIS_LIST | 列表 | “list” |
| REDIS_SET | 集合 | “set” |
| REDIS_ZSET | 有序集合 | “zset” |
| REDIS_HASH | 哈希 | “hash” |
注意,对于Redis中的任一键值对,键总是一个字符串对象,而值可以是上面5种对象的任意一种。比如说,列表键的意思是指,这个键对应的值是列表对象,其他类型对象以此类推。
TYPE命令用于返回对象类型。
2.2 对象编码
redisObject中的ptr指针指向对象使用的基础数据结构,而具体使用何种数据结构是由对象编码决定的。
encoding属性用于表示对象编码,说明这个对象使用的是何种数据结构。Redis 3.0中,encoding值可以是如下的任何一种:
| encoding | 使用的底层数据结构 |
|---|---|
| REDIS_ENCODING_RAW | SDS |
| REDIS_ENCODING_INT | long类型数 |
| REDIS_ENCODING_HT | 字典 |
| REDIS_ENCODING_LINKEDLIST | 双端链表 |
| REDIS_ENCODING_ZIPLIST | 压缩列表 |
| REDIS_ENCODING_INTSET | 整数集合 |
| REDIS_ENCODING_SKIPLIST | 跳表 |
| REDIS_ENCODING_EMBSTR | EMBSTR编码的SDS |
OBJECT ENCODING命令用于查看某个数据库键的值对象的编码。
每种类型的对象都使用了至少两种不同的编码,这使得Redis可以优化对象在不同场景下的效率和空间占用。
2.3 不同类型和编码的对象
| 对象类型 | 可能的编码类型 |
|---|---|
| 字符串 | long, embstr,raw |
| 列表 | 压缩列表、双端链表 |
| 哈希 | 压缩列表、字典 |
| 集合 | 整数集合、字典 |
| 有序集合 | 压缩列表、跳表 |
2. Redis中的五种对象类型
2.1 字符串对象
字符串对象有三种编码,可以是int, embstr, raw。使用何种编码是通过字符串对象保存的值类型和字符串长度决定,规则如下:
- 如果保存的是整数值,且整数不超过long范围,使用int编码
- 如果保存的是字符串值,且字符串长度 > 39, 使用raw编码
- 如果保存的是字符串值,且字符串长度 <= 39,使用embstr编码
对应redis源码中CreateStringObject的实现:
1 |
|
2.1.1 为什么需要embstr编码?
embstr编码是专门为保存短字符串的一种优化编码方式。和raw编码区别在于,embstr编码仅调用一次内存分配函数同时创建redisObject和sdshdr结构,优势如下:
- 内存分配、内存回收次数由两次降为一次。
- redisObject结构和sdshdr结构的内存是连续的、因此能更好地利用缓存。
以下分别给出raw编码和embstr编码的字符串对象示意图:
raw编码字符串:
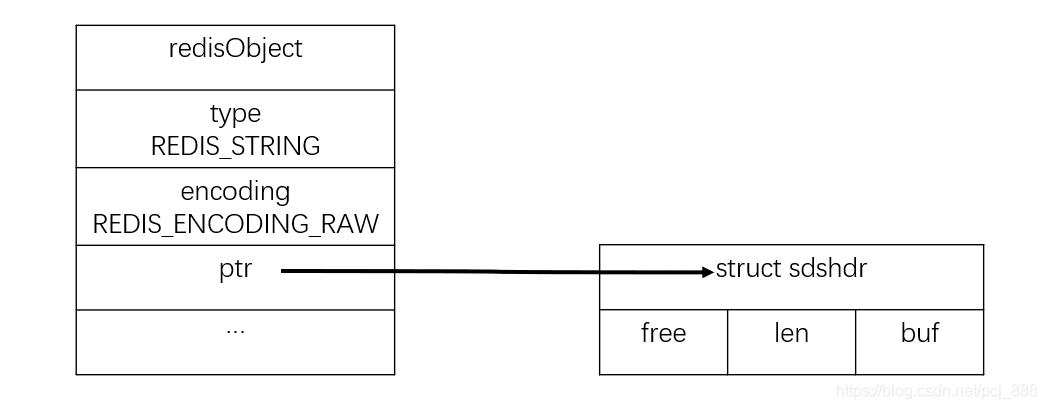
embstr编码字符串:
2.1.2 编码的转换
如果对int , embstr编码的字符串执行append操作,它们总是会转换为raw编码的字符串, 理由如下:
对int编码字符串做了append操作后,这个对象保存的就不再是整数值,所以编码必须发生转换。
对于embstr编码,Redis没有为embstr编码的字符串对象编写任何修改其内容的代码,所以append操作后embstr编码总转换成raw。也就是说,embstr编码的字符串为只读对象。
2.2 列表对象
列表对象编码可以是ziplist或linkedlist,创建列表对象代码如下:
1 | robj *createListObject(void); |
2.2.1 编码的转换
当列表对象同时满足以下两个条件时,列表对象使用ziplist编码,否则使用linkedlist编码
- 列表对象保存的所有字符串元素的长度都小于64字节
- 列表对象保存的元素个数小于512个
以上条件可以通过配置文件修改,相关配置项:list-max-ziplist-value, list-max-ziplist-entries
2.3 哈希对象
哈希对象编码可以是ziplist或hashtable,创建对象代码如下:
1 | robj *createHashObject(void); |
2.3.1 编码的转换
当哈希对象同时满足以下两个条件时,哈希对象使用ziplist编码,否则使用hashtable编码
- 哈希对象保存的所有键值对的键和值长度都小于64字节
- 哈希对象保存的键值对数少于512个
以上条件可以通过配置文件修改,相关配置项:hash-max-ziplist-value, hash-max-ziplist-entries
2.4 集合对象
集合对象编码可以是intset或hashtable
2.4.1 编码的转换
当集合对象可以同时满足以下两个条件时,对象使用intset编码,否则使用hashtable编码
- 集合对象保存的都是整数值。
- 集合对象保存的元素数量不超过512个。
以上条件可以通过配置文件修改, 相关配置项:set-max-intset-entries
2.5 有序集合对象
有序集合对象编码可以是ziplist或skiplist
基于skiplist编码的数据结构如下,可以看到有序集合对象同时使用了跳表和字典数据结构来实现。
1 | typedef struct zset { |
有序集合元素同时保存在跳表和字典,示意图如下: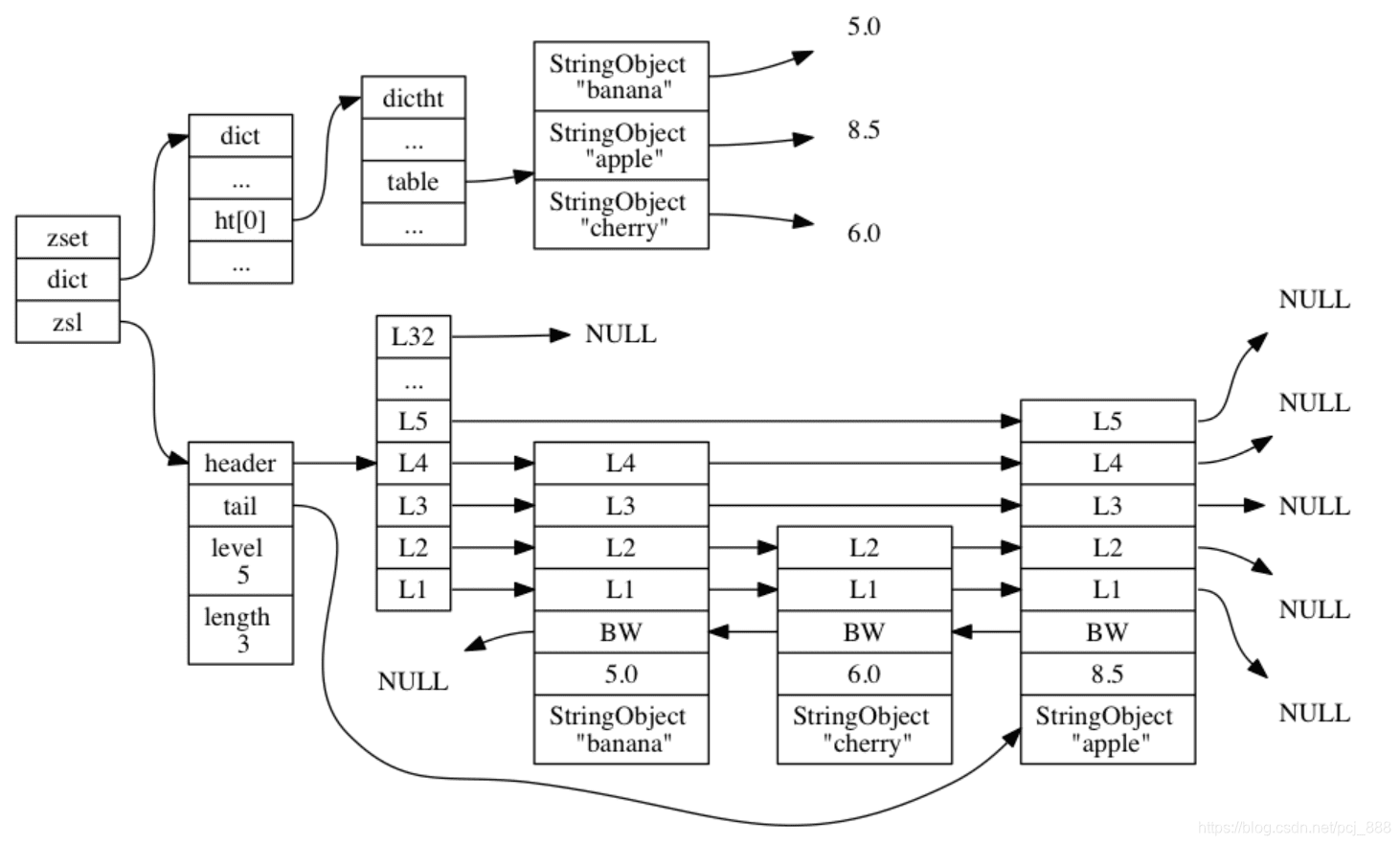
图中字典和跳表重复列出了各元素的成员和分数,而源码实现中,字典和跳表会共享元素的成员和分数,不会导致内存浪费。
2.5.1 为什么有序集合需要同时使用跳跃表和字典来实现?
如只使用字典,因为字典是无序的,执行范围操作时须先排序,复杂度O(NlogN),以及额外O(N)空间。
如只使用跳表,那么根据成员查找分数的操作效率较低,其复杂度为O(logN)。
2.5.2 编码的转换
有序集合对象可以同时满足以下两个条件,对象使用ziplist编码,否则使用skiplist编码
- 有序集合保存元素数量小于128个。
- 有序集合保存的所有元素成员都小于64个字节。
以上条件可以通过配置文件修改,相关配置项:zset-max-ziplist-entries,zset-max-ziplist-value
3. 内存回收机制
Redis是通过C语言实现的,C语言没有内存自动回收机制,因此Redis在对象系统中通过引用计数方式实现内存回收机制。
每个对象的引用计数信息通过redisObject结构中的refcount属性表示:
- 创建新对象时,引用计数初始为1
- 对象被新程序使用时,引用计数加1,参考
object.c/incrRefCount - 对象不再被程序使用时,引用计数减1,当引用计数减为0时回收内存,参考
object.c/decrRefCount
OBJECT REFCOUNT命令可以查看对象的引用计数。
4. 对象共享机制
对象的refcount属性除了用于实现内存回收机制外,还具有共享内存的作用。
比如,Redis服务器启动时会预先创建0 ~ 9999这1万个字符串对象。当redis需用到0 ~ 9999的字符串对象时,直接使用共享对象,不必每次都创建新对象,从而节约内存。源码参考object.c/createStringObjectFromLongLong
1 | // object.c |
4.1 为什么Redis只共享包含整数的对象?
- redis只共享包含数字的对象,是因为数字的复用场景最多。
- 出于CPU限制。在使用一个共享对象前,需要判断共享对象和目前对象是否相等。一个共享对象的值越复杂,这个判断的时间复杂度越高,越消耗CPU性能,注意到:
- 数字比较复杂度仅为O(1)
- 字符串比较复杂度为O(n)
- 对于更复杂的列表和哈希对象,比较复杂度上升到O(n ^ 2)。
5. 对象的空转时长
RedisObject的lru属性记录对象最后一次被命令程序访问的时间,可用于计算某个数据库键的空转时长。
OBJECT LDLETIME命令用于获取对象的空转时长,空转时长是通过当前时间减去对象的lru值计算得出。
空转时长可用于Redis服务器回收内存算法,原则是内存不足时,空转时长高的键优先被服务器释放,回收内存。
总结
- Redis的对象系统包含五种基本对象:字符串对象、列表对象、哈希对象、集合对象、有序集合对象。
- 每种类型的对象都使用了至少两种不同的编码,这使得Redis可以针对不同的场景,为对象设置多种不同的数据结构,优化对象在不同场景下的效率。
- Redis对象实现了基于引用计数的内存回收机制,对象共享机制,从而节约内存。
- Redis的对象带有访问事件记录信息,用于计算数据库键的空转时长,空转时长可以用于服务器的内存回收算法。
参考资料
《Redis设计与实现》 —— 第8章 对象

