体系结构 连接层 -> 服务层 -> 引擎层 —> 存储层
存储引擎 存储引擎指存储数据,建立索引,更新/查询数据等技术的实现方式。
查某个表的存储引擎 查数据库支持的存储引擎 创建表时指定引擎 1 2 3 4 5 create table a( )engine = MyISAM; create table b( )engine = InnoDB;
InnoDB
支持事务,行级锁,外键
每张表对应一个表空间文件XXX.ibd,路径:/var/lib/mysql/*.ibd
逻辑存储结构: TableSpace(表空间), Segment(段), Extent(区), Page(页), Row(行)
MyISAM MySQL早期的默认存储引擎
不支持事务,不支持外键
支持表锁,不支持行锁
XX.sdi 存储表结构信息, XX.MYD 存储数据 XX.MYI存储索引
Memory 表数据存储在内存中,只能将这些表作为临时表或缓存使用
内存存放
hash索引(默认)
XX.sdi 存储表结构
索引 索引(index)是帮助MySQL高效查询数据的数据结构。
索引结构
索引结构
描述
B+Tree索引
最常见索引, 大部分引擎都支持B+树索引
Hash索引
底层用哈希表实现,只有精确匹配索引列的查询才有效,不支持范围查询和排序
R-tree(空间索引)
MyISAM的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少
Full-text(全文索引)
一种通过建立倒排索引,快速匹配文档的方式,类似与Lucene,Solr,ES
为什么InnoDB选择B+树,不用二叉树,B树
二叉树:顺序插入时,退化成链表,查询性能低;层级较深,查询速度慢。
B-Tree: 叶子节点和非叶子节点都保存数据,查询不稳定;相比B+树IO消耗大
B+Tree: 只有叶子节点存储数据,使得树更矮,减少IO操作次数;所有叶子节点构成一个有序链表
索引分类
分类
含义
特点
关键字
主键索引
针对于表中主键创建的索引
默认自动创建,只有一个
PRIMARY
唯一索引
避免同一个表中某数据列的重复
可以有多个
UNIQUE
常规索引
快速定位特定数据
可以有多个
全文索引
查找文本中关键词
可以有多个
FULLTEXT
在InnoDB中,根据索引的存储形式,又可以分如下两种:
分类
含义
特点
聚集索引(Clustered Index)
将数据和索引一起存储,叶子节点保存了行数据
有且只有一个
二级索引(Secondary Index)
将数据和索引分开存储,叶子节点关联对应主键
可存在多个
聚集索引选取规则:
如果存在主键,主键索引就是聚集索引
如果不存在主键,使用第一个唯一索引作为聚集索引
如没有主键和合适的唯一索引,InnoDB会自动生成一个rowid作为隐藏的聚集索引
索引语法 创建索引
1 create [unique|fulltext] index index_name on table_name (index_col_name,...);
查看索引
1 show index from table_name;
删除索引
1 drop index index_name on table_name;
例:按如下要求完成索引的创建
1 2 3 4 5 6 7 8 9 10 11 create table tb_user( id bigint auto_increment primary key, name varchar (10 ), phone char (11 ), email varchar (36 ), profession varchar (36 ), age tinyint unsigned, gender char (1 ), status int , createtime datetime )engine= InnoDB;
要求:
name设置索引
phone非空创建唯一索引
profession,age,status设置联合索引
email建立索引
创建索引
1 2 3 4 create index idx_user_name on tb_user(name);create unique index idx_user_phone on tb_user(phone);create index idx_user_pro_age_sta on tb_user(profession,age,status);create index idx_user_email on tb_user(email);
查看索引
1 2 3 4 5 6 7 8 9 10 11 12 mysql> show index from tb_user; +---------+------------+----------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression | +---------+------------+----------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | tb_user | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | | YES | NULL | | tb_user | 0 | idx_user_phone | 1 | phone | A | 0 | NULL | NULL | YES | BTREE | | | YES | NULL | | tb_user | 1 | idx_user_name | 1 | name | A | 0 | NULL | NULL | YES | BTREE | | | YES | NULL | | tb_user | 1 | idx_user_pro_age_sta | 1 | profession | A | 0 | NULL | NULL | YES | BTREE | | | YES | NULL | | tb_user | 1 | idx_user_pro_age_sta | 2 | age | A | 0 | NULL | NULL | YES | BTREE | | | YES | NULL | | tb_user | 1 | idx_user_pro_age_sta | 3 | status | A | 0 | NULL | NULL | YES | BTREE | | | YES | NULL | | tb_user | 1 | idx_user_email | 1 | email | A | 0 | NULL | NULL | YES | BTREE | | | YES | NULL | +---------+------------+----------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
SQL性能分析 查询SQL执行频率 通过如下命令,查看SQL中增删改查的频率
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 mysql> show global status like 'Com_______'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | Com_binlog | 0 | | Com_commit | 0 | | Com_delete | 0 | | Com_import | 0 | | Com_insert | 0 | | Com_repair | 0 | | Com_revoke | 0 | | Com_select | 4 | | Com_signal | 0 | | Com_update | 0 | | Com_xa_end | 0 | +---------------+-------+
慢查询日志 记录所有执行时间超过指定参数long_query_time(默认:10秒)的所有SQL语句日志
MySQL的慢查询日志默认没有开,需要手动配置
1 2 3 4 5 6 7 mysql> show variables like 'slow_query%'; +---------------------+-----------------------------------+ | Variable_name | Value | +---------------------+-----------------------------------+ | slow_query_log | OFF | | slow_query_log_file | /var/lib/mysql/localhost-slow.log | +---------------------+-----------------------------------+
修改/etc/my.cnf.d/mysql-server.cnf, 在[mysqld]最后添加两行,开启MySQL慢查询日志,设置慢查询超时时间2秒
1 2 slow-query-log=on long_query_time=2
重启mysqld, 执行systemctl restart mysqld,再确认修改后的配置已生效
1 2 3 4 5 6 7 8 9 10 11 12 mysql> show variables like 'slow_query%'; +---------------------+-----------------------------------+ | Variable_name | Value | +---------------------+-----------------------------------+ | slow_query_log | ON | +---------------------+-----------------------------------+ mysql> show variables like 'long_query_time'; +-----------------+----------+ | Variable_name | Value | +-----------------+----------+ | long_query_time | 2.000000 | +-----------------+----------+
profile详情 先打开profile开关
1 2 3 4 5 6 7 8 9 mysql> select @@profiling; +-------------+ | @@profiling | +-------------+ | 0 | +-------------+ 1 row in set, 1 warning (0.00 sec) mysql> set profiling = 1;
执行SQL操作后,通过show profiles查看指令的执行耗时
1 2 3 4 5 6 7 8 9 mysql> show profiles; +----------+------------+------------------------------+ | Query_ID | Duration | Query | +----------+------------+------------------------------+ | 1 | 0.00027175 | select * from tb_user | | 2 | 0.00008450 | show profiles for query 1 | +----------+------------+------------------------------+ mysql> show profile for query 1; mysql> show profile cpu for query 1;
explain 1 explain select * from tb_user where id = 1;
实例:给tb_user表生成100w条数据,用于测试查询性能
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #!/usr/bin/env python3 import random from datetime import datetime, timedelta import string #insert into tb_user(name,phone,email,profession,age,gender,status,createtime) values('Jony','12345678111', 'example@163.com', 'RD',18,'M',1,NOW()); def generate_phone(): return '1' + ''.join([str(random.randint(0, 9)) for _ in range(10)]) def generate_random_date(): start_date = datetime(2024, 1, 1) end_date = datetime(2024, 12, 31) time_between_dates = end_date - start_date days_between_dates = time_between_dates.days random_number_of_days = random.randint(0, days_between_dates) random_date = start_date + timedelta(days=random_number_of_days) return random_date.strftime('%Y-%m-%d') def generate_random_name(length=5): letters = string.ascii_letters return ''.join(random.choice(letters) for _ in range(length)) def insert_data(): with open('./test.sql', 'w') as f: for i in range(1000000): name = generate_random_name() phone = generate_phone() email = generate_random_name() + '@163.com' profession = random.choice(['Sales', 'R&D', 'Marketing', 'OPS']) age = random.randint(0,130) gender = random.choice(['F','M']) status = random.choice([0, 1]) date = generate_random_date() output = "insert into tb_user(name,phone,email,profession,age,gender,status,createtime) values('{name}','{phone}', '{email}', '{profession}',{age},'{gender}', {status}, '{date}');".format(name=name, phone=phone, email=email, profession=profession, age=age, gender=gender, status=status, date=date) f.write(output + '\n') insert_data()
再从SQL文件中批量导入tb_user表的数据到数据库pc
1 mysql -u root -p -D pc < test.sql
explain执行计划中各字段含义
1 2 3 4 5 6 mysql> explain select name from tb_user where id = 1; +----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ | 1 | SIMPLE | tb_user | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL | +----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
id
select_type
type
possible_keys
key
key_len
rows
filtered
例: explain type = NULL (没有查表)
1 2 3 4 5 6 mysql> explain select 'A'; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+ | 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
例: explain type = const (走主键索引/唯一索引)
1 2 3 4 5 6 mysql> explain select name from tb_user where id = 1; +----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+ | 1 | SIMPLE | tb_user | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL | +----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
例: explain type = ref (走普通的非唯一索引)
1 2 3 4 5 6 mysql> explain select name from tb_user where name = 'uXrBh'; +----+-------------+---------+------------+------+---------------+---------------+---------+-------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+---------------+---------------+---------+-------+------+----------+-------------+ | 1 | SIMPLE | tb_user | NULL | ref | idx_user_name | idx_user_name | 43 | const | 1 | 100.00 | Using index | +----+-------------+---------+------------+------+---------------+---------------+---------+-------+------+----------+-------------+
索引应用 最左前缀法则
对于索引了多列的场景,最左前缀法则指查询从索引的最左列开始,且不跳过索引中的列
如果跳跃某一列,索引将部分失效(后面字段索引失效)
例:先查看tb_user表的索引
1 2 3 4 5 6 7 8 9 10 11 12 mysql> show index from tb_user; + | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression | + | tb_user | 0 | PRIMARY | 1 | id | A | 245768 | NULL | NULL | | BTREE | | | YES | NULL | | tb_user | 1 | idx_user_name | 1 | name | A | 269997 | NULL | NULL | YES | BTREE | | | YES | NULL | | tb_user | 1 | idx_user_pro_age_sta | 1 | profession | A | 3 | NULL | NULL | YES | BTREE | | | YES | NULL | | tb_user | 1 | idx_user_pro_age_sta | 2 | age | A | 535 | NULL | NULL | YES | BTREE | | | YES | NULL | | tb_user | 1 | idx_user_pro_age_sta | 3 | status | A | 1051 | NULL | NULL | YES | BTREE | | | YES | NULL | | tb_user | 1 | idx_user_phone | 1 | phone | A | 271498 | NULL | NULL | YES | BTREE | | | YES | NULL | | tb_user | 1 | idx_user_email | 1 | email | A | 269341 | NULL | NULL | YES | BTREE | | | YES | NULL | +
例: 符合最左前缀法则,走联合索引(profession,age,status)
1 2 3 4 5 6 mysql> explain select * from tb_user where profession = 'R&D' and age = 31 and status = 1; +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------------------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------------------+------+----------+-------+ | 1 | SIMPLE | tb_user | NULL | ref | idx_user_pro_age_sta | idx_user_pro_age_sta | 154 | const,const,const | 261 | 100.00 | NULL | +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------------------+------+----------+-------+
例:查询条件改成只有profession,仍然走联合索引(profession,age,status)
1 2 3 4 5 6 mysql> explain select * from tb_user where profession = 'R&D'; +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------+--------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------+--------+----------+-------+ | 1 | SIMPLE | tb_user | NULL | ref | idx_user_pro_age_sta | idx_user_pro_age_sta | 147 | const | 127438 | 100.00 | NULL | +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------+--------+----------+-------+
例:查询条件改成age, status,索引失效,走了全表扫描
1 2 3 4 5 6 mysql> explain select * from tb_user where age = 31 and status = 1; +----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | tb_user | NULL | ALL | NULL | NULL | NULL | NULL | 271498 | 1.00 | Using where | +----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
例:查询条件改成profession, status,索引部分失效,只有profession走了索引
1 2 3 4 5 6 mysql> explain select * from tb_user where profession = 'R&D' and status = 1; +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------+--------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------+--------+----------+-----------------------+ | 1 | SIMPLE | tb_user | NULL | ref | idx_user_pro_age_sta | idx_user_pro_age_sta | 147 | const | 127438 | 10.00 | Using index condition | +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------+--------+----------+-----------------------+
例:查询条件改成age, status, profession, 走联合索引(profession,age,status) (只要存在即可,和语句中的先后位置无关)
1 2 3 4 5 6 explain select * from tb_user where age = 31 and status = 1 and profession = 'R&D'; +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------------------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------------------+------+----------+-------+ | 1 | SIMPLE | tb_user | NULL | ref | idx_user_pro_age_sta | idx_user_pro_age_sta | 154 | const,const,const | 261 | 100.00 | NULL | +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------------------+------+----------+-------+
范围查询 联合索引中,出现范围查询,则范围查询右侧的列索引失效
例: age使用了范围查询,status没有走索引
1 2 3 4 5 6 mysql> explain select * from tb_user where profession = '软件工程' and age > 30 and status = '0'; +----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+ | 1 | SIMPLE | tb_user | NULL | range | idx_user_pro_age_sta | idx_user_pro_age_sta | 149 | NULL | 1 | 10.00 | Using index condition | +----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+
例:把 age > 30 改成 age >= 30,都可以走索引 (业务允许情况下,尽量用>=代替>)
1 2 3 4 5 6 mysql> explain select * from tb_user where profession = '软件工程' and age >= 30 and status = '0'; +----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+ | 1 | SIMPLE | tb_user | NULL | range | idx_user_pro_age_sta | idx_user_pro_age_sta | 154 | NULL | 1 | 10.00 | Using index condition | +----+-------------+---------+------------+-------+----------------------+----------------------+---------+------+------+----------+-----------------------+
在索引列上进行运算,索引会失效 例: 对phone做substring运算,发现索引失效, type = ALL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 mysql> explain select * from tb_user where phone = '10931949622'; +----+-------------+---------+------------+------+----------------+----------------+---------+-------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+----------------+----------------+---------+-------+------+----------+-----------------------+ | 1 | SIMPLE | tb_user | NULL | ref | idx_user_phone | idx_user_phone | 45 | const | 1 | 100.00 | Using index condition | +----+-------------+---------+------------+------+----------------+----------------+---------+-------+------+----------+-----------------------+ 1 row in set, 1 warning (0.00 sec) mysql> explain select * from tb_user where substring(phone,10,2) = '22'; +----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | tb_user | NULL | ALL | NULL | NULL | NULL | NULL | 271498 | 100.00 | Using where | +----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
字符串不加引号 字符串类型字段使用时,不加引号,索引将失效。
例:查询手机号时,忘了加引号,也能查出结果,但索引失效
1 2 3 4 5 6 mysql> explain select * from tb_user where phone = 10931949622; +----+-------------+---------+------------+------+----------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+----------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | tb_user | NULL | ALL | idx_user_phone | NULL | NULL | NULL | 271498 | 10.00 | Using where | +----+-------------+---------+------------+------+----------------+------+---------+------+--------+----------+-------------+
头部模糊匹配,索引失效 例: like查询手机号。使用头部模糊匹配’%262’,索引失效;尾部模糊匹配’109%’,索引有效
1 2 3 4 5 6 7 8 9 10 11 12 13 14 mysql> explain select * from tb_user where phone like '109%'; +----+-------------+---------+------------+-------+----------------+----------------+---------+------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------+----------------+----------------+---------+------+------+----------+-----------------------+ | 1 | SIMPLE | tb_user | NULL | range | idx_user_phone | idx_user_phone | 45 | NULL | 2713 | 100.00 | Using index condition | +----+-------------+---------+------------+-------+----------------+----------------+---------+------+------+----------+-----------------------+ 1 row in set, 1 warning (0.00 sec) mysql> explain select * from tb_user where phone like '%622'; +----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | tb_user | NULL | ALL | NULL | NULL | NULL | NULL | 271498 | 11.11 | Using where | +----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-------------+
or连接的条件 用or分割开的条件,如果or前条件中列有索引,or后条件没有索引,查询不会走索引
1 2 3 4 5 6 mysql> explain select * from tb_user where phone = '10931949622' or age = 23; +----+-------------+---------+------------+------+----------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+----------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | tb_user | NULL | ALL | idx_user_phone | NULL | NULL | NULL | 271498 | 10.00 | Using where | +----+-------------+---------+------------+------+----------------+------+---------+------+--------+----------+-------------+
数据分布情况也会影响是否使用索引 如果MySQL评估使用索引比全表更慢,则不使用索引
例: tb_user表数据profression都是not null的,使用where is not null查询没有走索引
1 2 3 4 5 6 mysql> explain select * from tb_user where profession is not null ; +----+-------------+---------+------------+------+----------------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+----------------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | tb_user | NULL | ALL | idx_user_pro_age_sta | NULL | NULL | NULL | 271498 | 50.00 | Using where | +----+-------------+---------+------------+------+----------------------+------+---------+------+--------+----------+-------------+
索引提示 SQL提示,是优化数据库的重要手段。指在SQL语句中加入一些认为提示来达到优化操作的目的。
例:先创建一个profession单列索引
1 mysql> create index idx_user_pro on tb_user(profession);
再查询profession为’R&D’的员工。MySQL可以用普通索引idx_user_pro,也可以用联合索引idx_user_pro_age_sta
1 2 3 4 5 6 mysql> explain select * from tb_user where profession = 'R&D'; +----+-------------+---------+------------+------+-----------------------------------+----------------------+---------+-------+--------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+-----------------------------------+----------------------+---------+-------+--------+----------+-------+ | 1 | SIMPLE | tb_user | NULL | ref | idx_user_pro_age_sta,idx_user_pro | idx_user_pro_age_sta | 147 | const | 127438 | 100.00 | NULL | +----+-------------+---------+------------+------+-----------------------------------+----------------------+---------+-------+--------+----------+-------+
use index (建议使用索引)
1 2 3 4 5 6 mysql> explain select * from tb_user use index(idx_user_pro) where profession = 'R&D'; +----+-------------+---------+------------+------+---------------+--------------+---------+-------+--------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+---------------+--------------+---------+-------+--------+----------+-------+ | 1 | SIMPLE | tb_user | NULL | ref | idx_user_pro | idx_user_pro | 147 | const | 127772 | 100.00 | NULL | +----+-------------+---------+------------+------+---------------+--------------+---------+-------+--------+----------+-------+
ignore index
1 2 3 4 5 6 mysql> explain select * from tb_user ignore index(idx_user_pro) where profession = 'R&D'; +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------+--------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------+--------+----------+-------+ | 1 | SIMPLE | tb_user | NULL | ref | idx_user_pro_age_sta | idx_user_pro_age_sta | 147 | const | 127438 | 100.00 | NULL | +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------+--------+----------+-------+
force index (强制使用索引)
1 2 3 4 5 6 mysql> explain select * from tb_user force index(idx_user_pro) where profession = 'R&D'; +----+-------------+---------+------------+------+---------------+--------------+---------+-------+-------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+---------------+--------------+---------+-------+-------+----------+-------+ | 1 | SIMPLE | tb_user | NULL | ref | idx_user_pro | idx_user_pro | 147 | const | 90499 | 100.00 | NULL | +----+-------------+---------+------------+------+---------------+--------------+---------+-------+-------+----------+-------+
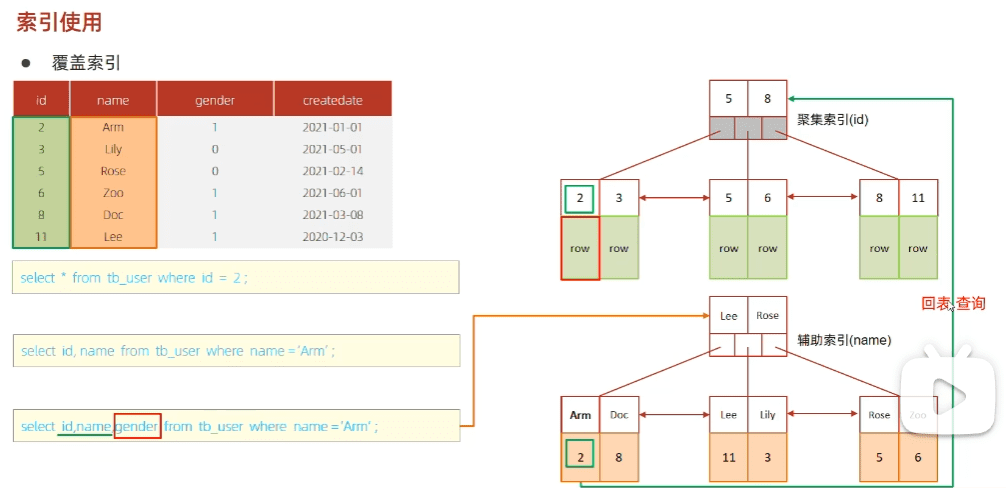
覆盖索引 查询使用到了索引,并且查询的所有列,在该索引中已经全部能够找到(不需要回表)
例: tb_user表已有联合索引(profession,age,status), 查询所有列在该索引中能找到时, Extra=’Using index’,当查询字段新增name时,Extra=’NULL’
1 2 3 4 5 6 7 8 9 10 11 12 13 14 mysql> explain select id,profession,age,status from tb_user where profession = 'R&D' and age = 31 and status = '0'; +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------------------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------------------+------+----------+-------------+ | 1 | SIMPLE | tb_user | NULL | ref | idx_user_pro_age_sta | idx_user_pro_age_sta | 154 | const,const,const | 249 | 100.00 | Using index | +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------------------+------+----------+-------------+ 1 row in set, 1 warning (0.00 sec) mysql> explain select id,profession,age,status,name from tb_user where profession = 'R&D' and age = 31 and status = '0'; +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------------------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------------------+------+----------+-------+ | 1 | SIMPLE | tb_user | NULL | ref | idx_user_pro_age_sta | idx_user_pro_age_sta | 154 | const,const,const | 249 | 100.00 | NULL | +----+-------------+---------+------------+------+----------------------+----------------------+---------+-------------------+------+----------+-------+
注:
using index condition (查找使用了索引,但需要回表)
using where; using index; (查找使用了索引,且需要数据都能在索引列中找到,无需回表)
聚集索引和辅助索引
聚集索引
辅助索引 叶子节点存主键ID (聚集索引叶子节点已经存储行数据,没必要每个辅助索引也存一份行数据,只存主键ID节省空间)
前缀索引 当字段类型为字符串(varchar,text)时,可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率
语法:
1 create index idx_XXX on table_name(column (n));
前缀长度
1 select count(distinct substring(email, 1, 5)/count(*) from tb_user;
例: 给email建立前缀索引,取长度为5
1 create index idx_email_5 on tb_user(email(5));
单列索引与联合索引 联合索引指一个索引包含了多个列。
SQL优化 插入数据 主键优化 order by优化 using filesort: 在排序缓冲区sort buffer中完成排序操作,未通过索引直接返回排序结果
例: 没有建立索引,排序查询走Using filesort.
1 2 3 4 5 6 mysql> explain select id, age, phone from tb_user order by age; +----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+----------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+----------------+ | 1 | SIMPLE | tb_user | NULL | ALL | NULL | NULL | NULL | NULL | 271498 | 100.00 | Using filesort | +----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+----------------+
例:建立索引,排序查询走Using index
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 mysql> create index idx_user_age_phone on tb_user(age,phone); mysql> explain select id, age, phone from tb_user order by age,phone; +----+-------------+---------+------------+-------+---------------+--------------------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------+---------------+--------------------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | tb_user | NULL | index | NULL | idx_user_age_phone | 47 | NULL | 271498 | 100.00 | Using index | +----+-------------+---------+------------+-------+---------------+--------------------+---------+------+--------+----------+-------------+ mysql> explain select id, age, phone from tb_user order by age desc ,phone desc; +----+-------------+---------+------------+-------+---------------+--------------------+---------+------+--------+----------+----------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------+---------------+--------------------+---------+------+--------+----------+----------------------------------+ | 1 | SIMPLE | tb_user | NULL | index | NULL | idx_user_age_phone | 47 | NULL | 271498 | 100.00 | Backward index scan; Using index | +----+-------------+---------+------------+-------+---------------+--------------------+---------+------+--------+----------+----------------------------------+ mysql> explain select id, age, phone from tb_user order by age asc ,phone desc; +----+-------------+---------+------------+-------+---------------+--------------------+---------+------+--------+----------+-----------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------+---------------+--------------------+---------+------+--------+----------+-----------------------------+ | 1 | SIMPLE | tb_user | NULL | index | NULL | idx_user_age_phone | 47 | NULL | 271498 | 100.00 | Using index; Using filesort | +----+-------------+---------+------------+-------+---------------+--------------------+---------+------+--------+----------+-----------------------------+
注:
使用排序字段建立合适索引,多字段排序时也遵循最左前缀法则
尽量使用覆盖索引
多字段排序,一个升序一个降序,需指定联合索引创建的规则(ASC/DESC)
如果不可避免出现filesort,大数量排序时可适当增加排序缓冲区大小sort_buffer_size(默认256k)1 2 3 4 5 6 mysql> show variables like 'sort_buffer_size'; +------------------+--------+ | Variable_name | Value | +------------------+--------+ | sort_buffer_size | 262144 | +------------------+--------+
group by优化 先删除所有索引,测试group by查询结果为Using temporary(效率很低)
1 2 3 4 5 6 mysql> explain select profession,count(*) from tb_user group by profession; +----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-----------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-----------------+ | 1 | SIMPLE | tb_user | NULL | ALL | NULL | NULL | NULL | NULL | 271498 | 100.00 | Using temporary | +----+-------------+---------+------------+------+---------------+------+---------+------+--------+----------+-----------------+
创建索引后,测试group by查询结果为Using index
1 2 3 4 5 6 7 mysql> create index idx_pro_age_sta on tb_user(profession,age,status); mysql> explain select profession,count(*) from tb_user group by profession; +----+-------------+---------+------------+-------+-----------------+-----------------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------+-----------------+-----------------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | tb_user | NULL | index | idx_pro_age_sta | idx_pro_age_sta | 154 | NULL | 271498 | 100.00 | Using index | +----+-------------+---------+------------+-------+-----------------+-----------------+---------+------+--------+----------+-------------+
limit优化 分页的记录越靠后,查询耗时越大。
例:
1 2 select * from tb_sku order by id limit 9000000,10; select s.* from tb_sku s, (select id from tb_sku order by id limit 900000,10) a where s.id = a.id;
count优化 表数据量大时, count(*)执行耗时较多
count(主键)
count(字段)
count(1)
count(*)
总结: count(*)效率最高
update优化 更新数据时,一定要根据索引更新,否则会出现锁表的现象。
例: 没有对name建立索引的条件下,以下update语句会锁住整张表
1 update student set no = '123' where name = 'haha';
视图 视图(View)是一种虚拟存在的表,视图仅保存查询的SQL逻辑,不保存查询结果。
创建视图
1 create view tb_user_v1 as select id, name from tb_user where id <= 10;
查询视图
1 select * from tb_user_v1;
修改视图
1 alter view tb_user_v1 as select id from tb_user where id <= 10;
删除
检查选项cascade 视图可以插入数据,通过视图插入的数据不一定能在视图中查询到(比如插入id>10的记录)
例: 创建视图时指定with cascaded check option,可以阻止通过视图插入查不到的数据
1 2 3 4 mysql> create or replace view tb_user_v1 as select id, name from tb_user where id <= 10 with cascaded check option; mysql> insert into tb_user_v1(id,name) values(100,'hello'); ERROR 1369 (HY000): CHECK OPTION failed 'pc.tb_user_v1'
存储过程 创建过程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 delimiter $$ create procedure p1() begin select count(*) from tb_user; end$$ delimiter ; mysql> call p1(); +----------+ | count(*) | +----------+ | 272633 | +----------+ 1 row in set (0.02 sec)
查看过程 1 2 select * from information_schema.ROUTINES where ROUTINE_SCHEMA = 'itcast'; show create procedure 存储过程名称;
删除过程 1 drop procedure if exists p1;
变量
全局变量(GLOBAL)
会话变量(SESSION)
查看系统变量 1 2 3 show [session|global] variables; show [session|global] variables like '...'; select @@[session|global].变量;
设置系统变量 1 set [session|global] 系统变量名=值;
注:
未指定session或global时,默认为session,会话级变量
mysql重启后,所设置全局参数会失效,要想不失效,可以在/etc/my.cnf中配置。
用户定义和使用变量 1 2 set @var_name := expr [, @var_name = expr]; -- 定义变量 select @var_name; -- 使用变量
注:用户定义变量无需对其进行声明或初始化,只不过获取到的值为NULL
if语句 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 create procedure p3() begin declare score int default 58; declare result varchar(10); if score >= 85 then set result := '优秀'; elseif score >= 60 then set result := '及格'; else set result := '不及格'; end if select result; end; call p3();
参数 例:入参为分数,出参为(优秀,及格,不及格)
1 2 3 4 5 6 7 8 9 10 11 12 13 create procedure p4(in score int, out result varchar(10)) begin if score >= 85 then set result := '优秀'; elseif score >= 60 then set result := '及格'; else set result := '不及格'; end if select result; end; call p4(68, @result);
case 例:求月份所属季度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 create procedure p6(in month int) begin declare result varchar(10); case when month >= 1 and month <= 3 then set result := '第一季度'; when month >= 4 and month <= 6 then set result := '第二季度'; when month >= 7 and month <= 9 then set result := '第三季度'; when month >= 10 and month <= 12 then set result := '第四季度'; else set result := '非法参数'; end case; select concat('输入月份为: ', month, ', 所属季度为: ', result); end; call p6(4);
while 例: 计算从1累加到n的和
1 2 3 4 5 6 7 8 9 10 11 create procedure p7(in n int) begin declare total int default 0; while n>0 do set total := total + n; set n := n + 1; end while; select total; end; call p7(10);
repeat 例:计算从1累加到n的和
1 2 3 4 5 6 7 8 9 10 11 create procedure p8(in n int) begin declare total int default 0; repeat set total := total + n; set n := n - 1; until n <= 0 end repeat; select total; end;
游标(cursor) 用来存储查询结果集的数据类型
例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 create procedure p11(in uage int) begin declare u_cursor cursor for select name,profession from tb_user where age <= uage; declare uname varchar(100); declare upro varchar(100); declare exit handler for SQLSTATE '02000'; drop table if exists tb_user_pro; create table if not exists tb_user_pro( id int primary key auto_increment, name varchar(100), profession varchar(100) ); open u_cursor; while true do fetch u_cursor into uname,upro; insert into tb_user_pro values(null,uname,upro); end while; close u_cursor; end; call p11(40);
存储函数 存储函数是有返回值的存储过程,参数只能是IN类型。
例:从1到n累加
1 2 3 4 5 6 7 8 9 10 11 create function fun1(n int) returns int begin declare total int default 0; while n>0 do set total := total + n; set n := n - 1; end while; return total; end;
锁(重点) 锁是计算机协调多个进程或线程并发访问某一资源的机制
全局锁: 锁定数据库中的所有表
表级锁: 每次操作锁住整张表
行级锁: 每次操作锁住对应的行数据
全局锁 对整个数据库实例加锁,加锁后整个实例处于只读状态,后续的DML写语句,DDL语句都被阻塞。
全局锁实例
1 2 3 4 5 6 7 8 9 10 11 12 13 flush table with read lock; update tb_user set name = 'XXX' where id = 1 ;ERROR 1223 (HY000): Can't execute the query because you have a conflicting read lock -- 但是不能写 update tb_user set name = ' XXX' where id = 1; ERROR 1223 (HY000): Can' t execute the query because you have a conflicting read lockunlock tables;
注:数据库中加全局锁,是一个比较重的操作,存在以下问题:
表级锁 表级锁分为如下三类
表锁
元数据锁 (meta data lock, MDL)
意向锁
表锁
表共享读锁(read lock)
表独占写锁(write lock)
语法
读锁的特点
1 2 3 4 5 6 7 8 9 10 11 12 mysql> lock tables tb_user read; mysql> select * from tb_user where id = 1; +----+-------+-------------+---------------+ | id | name | phone | email | +----+-------+-------------+---------------+ | 1 | uXrBh | 15847705582 | YYdRR@163.com | +----+-------+-------------+---------------+ mysql> update tb_user set name = 'XXX' where id = 1; ERROR 1099 (HY000): Table 'tb_user' was locked with a READ lock and can't be updated mysql> unlock tables
b) 客户端c1加了写锁后, c1能读也能写,但c2不能读也不能写。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 -- 客户端c1 mysql> lock table tb_user write; mysql> update tb_user set name = 'XXXXX' where id = 1; Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> select * from tb_user where id = 1; +----+-------+-------------+---------------+------------+------+--------+--------+---------------------+ | id | name | phone | email | profession | age | gender | status | createtime | +----+-------+-------------+---------------+------------+------+--------+--------+---------------------+ | 1 | XXXXX | 15847705582 | YYdRR@163.com | OPS | 81 | F | 0 | 2024-08-22 00:00:00 | +----+-------+-------------+---------------+------------+------+--------+--------+---------------------+ -- 客户端c2 -- 不能读,被阻塞 mysql> select * from tb_user limit 1; ^C^C -- query aborted ERROR 1317 (70100): Query execution was interrupted -- 不能写,直接报错 mysql> mysql> update tb_user set name = 'XXX' where id = 1; ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'mysql> update tb_user set name = 'XXX' where id = 1' at line 1
元数据锁(meta data lock, MDL)
MDL加锁是系统自动控制,无需显式使用,访问一张表时会自动加上。
MDL锁作用是维护表元数据的一致性,表上有活动事务时,不可以对元数据进行写入操作。
MySQL5.5中引入MDL,对一张表进行增删改查时,加MDL读锁(共享), 对表结构进行变更时,加MDL写锁(排他)。避免了DML与DDL的冲突,保证读写正确性。
对应SQL
锁类型
说明
lock tables xxx read/write
SHARED_READ_ONLY/SHARED_NO_READ_WRITE
select, select … lock in share mode
SHARED_READ
与SHARED_READ, SHARED_WRITE兼容, 与EXCLUSIVE互斥
insert, update, delete, select … for update
SHARED_WRITE
与SHARD_READ, SHARED_WRITE兼容, 与EXCLUSIVE互斥
alter table …
EXCLUSIVE
与其他MDL互斥
元数据锁的特点
1 2 3 4 5 6 7 8 9 10 11 12 13 -- 客户端c1手动开启事务,执行select操作, 不提交 mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from demo; Empty set (0.00 sec) -- 客户端c2开启事务,执行alter table,发现被阻塞 (EXCLUSIVE与SHARED_READ互斥) mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> alter table demo add column1 int; b^
查看元数据锁的指令:
1 select object_type,object_schema,object_name,lock_type,lock_duration from performance_schema.metadata_locks;
意向锁 为了避免DML执行时,加的行锁与表锁冲突,InnoDB引入意向锁,使得表锁不用检查每行数据是否有锁,使用意向锁减少表锁的检查。
意向锁有两种:
意向共享锁(IS): 由语句select … lock in share mode添加
意向排他锁(IX): 由insert,update,delete,select … for update添加
意向锁兼容性:
意向共享锁(IS): 与表锁共享锁兼容,与其他表锁互斥。
意向排他锁(IX): 与表锁共享锁及排它锁都互斥,意向锁之间不会互斥。
可以通过以下SQL,查看意向锁及行锁的加锁情况:
1 select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks;
意向锁1实例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 -- 客户端c1开启事务,加IS锁+行锁 mysql>begin; mysql>select * from demo where id = 1 lock in share mode; mysql> select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks; +---------------+-------------+-----------------+-----------+-----------+------------------------+ | object_schema | object_name | index_name | lock_type | lock_mode | lock_data | +---------------+-------------+-----------------+-----------+-----------+------------------------+ | pc | demo | NULL | TABLE | IS | NULL | | pc | demo | GEN_CLUST_INDEX | RECORD | S | supremum pseudo-record | | pc | demo | GEN_CLUST_INDEX | RECORD | S | 0x000000000300 | +---------------+-------------+-----------------+-----------+-----------+------------------------+ -- 此时,客户端c2可以加表共享读锁,但不能加表排他写锁。 mysql> lock tables demo read; Query OK, 0 rows affected (0.00 sec) mysql> unlock tables; Query OK, 0 rows affected (0.00 sec) mysql> lock tables demo write; ^C^C -- query aborted ERROR 1317 (70100): Query execution was interrupted
行级锁 行级锁,每次操作锁住对应的行数据,锁定粒度最小,发生锁冲突概率最低,并发度最高。应用在InnoDB存储引擎中。
行锁(Record Lock)
间隙锁(Gap Lock) RR隔离级别下支持
临键锁(Next-Key Lock)
行锁
共享锁(S):允许一个事务读一行,阻止其他事务获得排它锁。
排它锁(X):允许获取排它锁事务更新数据,阻止其他事务获得相同数据集的共享锁和排他锁。
SQL
行锁类型
说明
insert
排他锁
自动加锁
update
排他锁
自动加锁
delete
排他锁
自动加锁
select
不加锁
select … lock in share mode
共享锁
需手动在select之后加lock in share mode
select … for update
排它锁
需要手动在select之后加for update
行锁示例:
针对唯一索引进行检索时,对已存在记录进行等值匹配时,自动优化为行锁。
不通过索引条件检索数据,InnoDB将对表中所有记录加锁,此时升级为表锁。
触发器 触发器是与表有关的数据库对象,指在insert/update/delete之前或之后,触发并执行触发器中定义的SQL语句集合。
触发器类型
NEW和OLD
INSERT型触发器
NEW表示将要或者已经新增的数据
UPDATE型触发器
OLD表示修改之前的数据,NEW表示将要或已经修改后的数据
DELETE型触发器
OLD表示将要或者已经删除的数据
– TODO –
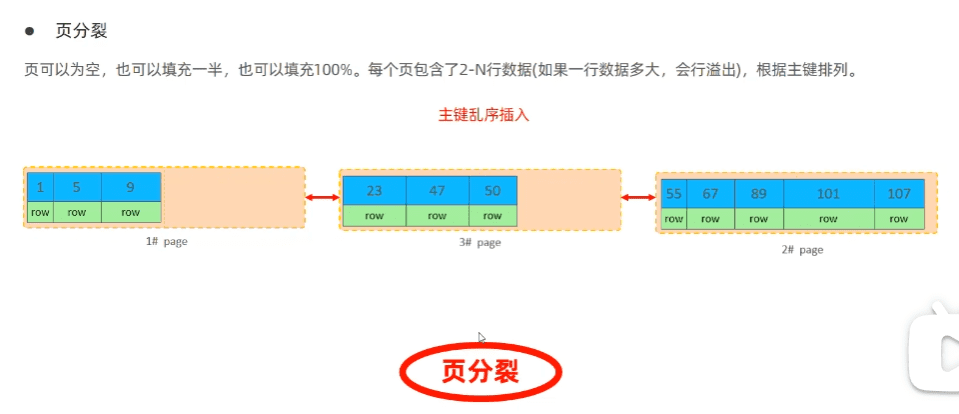
InnoDB引擎 逻辑存储结构 Tablespace(表空间) -> Segment(段) -> Extent(区) -> Row(行) -> Page(页)
表空间(ibd文件), 一个MySQL示例可对应多个表空间,用于存储记录,索引等数据。
表空间
1 2 3 4 # ls /var/lib/mysql/*.ibd /var/lib/mysql/mysql.ibd # ls /var/lib/mysql/pc/ demo.ibd tb_user.ibd
架构 Buffer Pool 缓冲池: 缓存磁盘上经常操作的数据,执行增删改查操作时,先操作Buffer Pool数据(如Buffer Pool没有数据,就从磁盘加载并缓存),再以一定频率刷到磁盘,从而减少磁盘IO,加快处理速度
free page 空闲页,未被使用
clean page 被使用页,数据没有被修改过
dirty page 被使用页,数据与磁盘中不一致
Change Buffer 更改缓冲区,执行DML语句时,如果这些数据Page没有在Buffer Pool中,不会直接操作磁盘,而是将数据变更存到Change Buffer,
Adaptive Hash Index (自适应哈希索引)
自适应哈希索引,用于优化对Buffer Pool数据查询。InnoDB会监控对表上各索引页查询,如观察到hash索引可以提升速度,
自适应哈希索引,无需人工干预,是系统根据情况自动完成的1 2 3 4 5 6 7 mysql> show variables like '%hash_index%'; +----------------------------------+-------+ | Variable_name | Value | +----------------------------------+-------+ | innodb_adaptive_hash_index | ON | | innodb_adaptive_hash_index_parts | 8 | +----------------------------------+-------+
Log Buffer 用于保存要写入到磁盘中的log(redo log, undo log), 默认大小16MB,参数:
innodb_log_buffer_size 缓冲区大小
innodb_flush_log_at_trx_commit 日志刷新到磁盘时机
磁盘结构
System Tablespace: 系统表空间是更改缓冲区的存储区域,如果表是在系统表空间而不是每个表文件或通用表空间中创建的,也可能含表和索引数据
1 2 3 4 5 6 mysql> show variables like '%data_file_path%'; +----------------------------+------------------------+ | Variable_name | Value | +----------------------------+------------------------+ | innodb_data_file_path | ibdata1:12M:autoextend | +----------------------------+------------------------+
File-Per-Table Tablespaces: 每个表的文件表空间包含单个InnoDB表数据和索引,并存储在文件系统的单个数据文件中
1 2 3 4 5 6 mysql> show variables like '%innodb_file_per_table%'; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | innodb_file_per_table | ON | +-----------------------+-------+
Gerneral Tablespaces: 通用表空间,需通过craete tablespace语法创建通用表空间,创建表时可以指定该表空间
Undo Tablespaces: 撤销表空间,MySQL实例在初始化时会自动创建两个默认undo表空间,用于存储undo log
Doublewrite Buffer Files: 双写缓冲区,innoDB将数据页从Buffer Pool刷新到磁盘前,先将数据页写入双写缓冲区文件中,便于系统异常时恢复数据。
Redo Log: 重做日志,两部分组成(redo log buffer, redo log),当事务提交后会把所有修改信息存到日志中,用于刷新脏页到磁盘发生错误时,进行数据恢复
后台线程
Master Thread 核心线程,负责调度其他线程,将缓冲池中数据异步刷新到磁盘,包括脏页刷新,合并插入缓存,undo页回收
IO Thread InnoDB使用AIO处理IO请求
线程类型
默认个数
职责
Read Thread
4
负责读操作
Write Thread
4 负责写操作
Log Thread
1
负责将日志缓冲区刷新到磁盘
Insert Buffer Thread
1
负责将缓冲区内容刷新到磁盘
事务原理 redo log 重做日志,记录事务提交时数据页的物理修改,用来实现事务的持久性,由两部分组成
redo log buffer(内存)
redo log file(磁盘)
undo log 回滚日志,记录数据被修改前的信息,作用:提供回滚, MVCChttps://www.bilibili.com/video/BV1Kr4y1i7ru?spm_id_from=333.788.player.switch&vd_source=d8559c2d87607be86810cd806158bb86&p=140
MVCC MVCC的几个重要概念:
当前读
例: 先在客户端c1开启事务, 再从客户端c2更新tb_user表id=1记录并提交,此时c1不能查到c2修改的记录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 -- 客户端c1开启事务 mysql> begin; mysql> select * from tb_user; +----+-------+ | id | value | +----+-------+ | 1 | 1 | +----+-------+ 1 row in set (0.00 sec) -- 客户端c2更新tb_user表id=1记录,并提交事务 mysql> begin; mysql> update tb_user set value = 2 where id = 1; mysql> commit; -- 切到客户端c1,此时c1中查不到c2修改的记录, 即可重复读 mysql> select * from tb_user; +----+-------+ | id | value | +----+-------+ | 1 | 1 | +----+-------+ -- 如果通过select * lock in share mode 使用当前读,就可以查到c2修改的记录 mysql> select * from tb_user lock in share mode; +----+-------+ | id | value | +----+-------+ | 1 | 2 | +----+-------+
快照读
read committed: 每次select都生成一个快照读
Repeatable Read: 开启事务后第一个select语句才是快照读
Serializable: 快照读退化为当前读
MVCC
MVCC实现原理 记录中的隐藏字段
隐藏字段
含义
DB_TRX_ID
最近修改事务ID,记录插入这条记录或最后一次修改改记录的事务ID
DB_ROLL_PTR
回滚指针, 指向这条记录的上一个版本,用于配合undo log, 指向上一个版本
DB_ROW_ID
隐藏主键, 如果表结构没有指定主键。将会生成该隐藏字段
查看隐藏字段
1 ibd2sdi /var/lib/mysql/pc/tb_user.ibd
undo log
当insert时候,产生的undo log只在回滚时需要,事务提交后可被立即删除。
而update,delete时候,产生的undo log不仅在回滚时需要,在快照读时也需要,不会被立即删除。
undo log版本链
** readview **
字段
含义
m_ids
当前活跃的事务ID集合
min_trx_id
最小活跃事务ID
max_trx_id
预分配事务ID, 当前最大事务ID+1
creator_trx_id
ReadView创建者的事务ID
trx_id == creator_trx_id 可以访问该版本, 说明数据是当前这个事务更改的
trx_id < min_trx_id 可以访问该版本, 说明数据已经提交了
trx_id > max_trx_id 不可以访问该版本, 说明该事务在ReadView生成后才开启
min_trx_id <= trx_id <= max_trx_id 如果trx_id不在m_ids中是可以访问该版本的
不同的隔离级别,生成readview的时机不同:
READ COMMITTED: 在事务中每一次执行快照读时生成Read View
REPEATABLE READ: 仅在事务中第一次执行快照读时生成ReadView, 后续复用该ReadView (可重复读)
MySQL管理 系统数据库
mysql 存储MySQL正常运行所需各种信息(时区、主从、用户、权限)
information_schema 提供了访问数据库元数据的各种表和视图,包含数据库,表,字段类型以及访问权限
performance_schema 为MySQL运行时状态提供了一个底层监控功能,主要用于收集数据库服务器性能参数
sys 包含一系列方便DBA和开发人员利用performance_schema性能数据库进行性能调优和诊断的视图
常用工具 mysql 例: 通过mysql -e直接执行语句,无需进入交互式命令行 (用户名root,密码123,数据库名称pc)
1 mysql -uroot -p123 pc -e "select * from tb_user"
mysqladmin 一个执行管理操作的客户端程序,可以用它检查服务器配置和当前状态,创建并删除数据库等。
mysqlbinlog 检查二进制日志
1 mysqlbinlog -s binlog.000006 /var/lib/mysql/binlog.000006
mysqlshow mysqlshow客户端对象查找工具,用来很快查找存在哪些数据库,数据库中的表,表中的列或者索引。
1 2 3 4 5 6 7 8 9 10 11 12 13 # mysqlshow -uroot -pXXXXXX --count mysqlshow: [Warning] Using a password on the command line interface can be insecure. +--------------------+--------+--------------+ | Databases | Tables | Total Rows | +--------------------+--------+--------------+ | gx_day15 | 12 | 70 | | gx_day16 | 14 | 75 | | information_schema | 79 | 29745 | | mysql | 37 | 4090 | | pc | 3 | 2 | | performance_schema | 111 | 295786 | | sys | 101 | 6398 | +--------------------+--------+--------------+
mysqldump mysqldump用于备份数据库和在不同数据库间作数据迁移。备份内容包含创建表,以及插入表的SQL语句
1 mysqldump -uroot -ppassword dbname > output.sql
查看MySQL版本 https://github.com/mysql/mysql-server/releases/tag/mysql-8.0.36
进程模型 1 2 systemctl cat mysqld | grep ExecStart= ExecStart=/usr/libexec/mysqld --basedir=/usr
单进程多线程模型
1 2 3 4 5 6 7 8 ps axf | grep mysqld 16273 ? Ssl 0:33 /usr/libexec/mysqld --basedir=/usr ps -T 16273 PID SPID TTY STAT TIME COMMAND 16273 16273 ? Ssl 0:00 /usr/libexec/mysqld --basedir=/usr 16273 16276 ? Ssl 0:00 /usr/libexec/mysqld --basedir=/usr 16273 16277 ? Ssl 0:00 /usr/libexec/mysqld --basedir=/usr ....
https://www.jcwlyf.com/newsContent-id-18272.html
mysqld进程
监听线程,接受客户端连接请求;
查询线程,处理客户端发来的SQL查询;
复制线程,处理主从复制相关操作;
后台线程,执行定期任务如日志清理、缓存刷新等。