集群规划 8台Linux虚拟机, Rocky Linux 9.5 x86_64
主节点(3个): 2CPU, 3G内存, 20G硬盘
工作节点(2个): 2CPU, 3G内存, 20G硬盘
LB(2个): 1CPU, 2G内存, 10G硬盘
各个机器IP、主机名、角色如下
1 2 3 4 5 6 7 8 9 10 11 192.168.52.91 k8s-master1 主节点1 192.168.52.92 k8s-master2 主节点2 192.168.52.93 k8s-master3 主节点3 192.168.52.101 k8s-slave1 从节点1 192.168.52.102 k8s-slave2 从节点2 192.168.52.103 k8s-slave3 从节点3 192.168.52.80 k8s-lb1 HAProxy 192.168.52.81 k8s-lb2 HAProxy 192.168.52.88 www.petertest.com Virtual IP(VIP)
以下分步搭建kubernetes集群
搭建一主一从集群
添加负载均衡(HAProxy)
搭建三主三从集群(三主三从两LB)
一、搭建一主一从集群 0. 准备工作 创建两台虚拟机, 1台作为主节点, 1台作为工作节点
1 2 192.168.52.91 k8s-master1 主节点1 192.168.52.101 k8s-slave1 从节点1
更新系统软件包 修改主机名 1 hostnamectl set-hostname XXX
修改hosts文件 1 2 3 4 5 6 7 8 9 10 11 192.168.52.91 k8s-master1 192.168.52.92 k8s-master2 192.168.52.93 k8s-master3 192.168.52.101 k8s-slave1 192.168.52.102 k8s-slave2 192.168.52.103 k8s-slave3 192.168.52.80 k8s-lb1 192.168.52.81 k8s-lb2 192.168.52.88 www.petertest.com
关闭防火墙 1 2 systemctl stop firewalld systemctl disable firewalld
关闭SELINUX 1 2 setenforce 0 sed --follow-symlinks -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
禁用交换分区 kubelet默认行为是在节点上检测到交换内存时无法启动,所以这里先禁用交换分区。临时禁用交换分区方法:
永久禁用交换分区,修改/etc/fstab, 注释掉swap分区那一行的配置
1 sed -i '/\/dev\/mapper\/rl-swap/s/^/#/' /etc/fstab
加载内核模块, 再设置内核参数 临时加载内核模块
1 2 3 modprobe ip_vs_rr modprobe br_netfilter modprobe overlay
每次启动时自动加载内核模块
1 2 3 4 5 cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf br_netfilter overlay ip_vs_rr EOF
再设置内核参数
1 2 3 4 5 6 7 cat <<EOF | tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 EOF sysctl -p /etc/sysctl.d/k8s.conf
1. 安装containerd, kubeadm, kubelet, kubectl 国内机器需要更换YUM源
1 2 3 4 5 sed -e 's|^mirrorlist=|#mirrorlist=|g' \ -e 's|^#baseurl=http://dl.rockylinux.org/$contentdir|baseurl=https://mirrors.aliyun.com/rockylinux|g' \ -i.bak \ /etc/yum.repos.d/[Rr]ocky-*.repo dnf makecache
安装containerd 1 2 3 dnf config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo # 国内用阿里源 #dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo dnf install -y containerd
配置containerd 1 containerd config default > /etc/containerd/config.toml
再修改/etc/containerd/config.toml
把SystemdCGroup的值改成true
把sandbox_image改为registry.aliyuncs.com/google_containers/pause:3.9 (国内用户需要做这一步,把镜像换成阿里的)
启动containerd 1 2 systemctl daemon-reload systemctl enable --now containerd
查看containerd版本
1 2 3 4 5 6 7 8 9 10 # ctr version Client: Version: 1.7.25 Revision: bcc810d6b9066471b0b6fa75f557a15a1cbf31bb Go version: go1.22.10 Server: Version: 1.7.25 Revision: bcc810d6b9066471b0b6fa75f557a15a1cbf31bb UUID: 086ce061-3335-48a7-9b78-67b3f12c43ef
安装kubeadm, kubelet, kubectl 先添加k8s的repo
1 2 3 4 5 6 7 8 9 cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF
再通过yum安装kubelet, kubeadm, kubectl
1 2 yum install -y kubelet kubeadm kubectl systemctl enable --now kubelet
查看kubelet, kubeadm, kubectl版本
1 2 3 4 5 6 7 8 9 10 kubeadm version kubeadm version: &version.Info{Major:"1", Minor:"28", GitVersion:"v1.28.2", GitCommit:"89a4ea3e1e4ddd7f7572286090359983e0387b2f", GitTreeState:"clean", BuildDate:"2023-09-13T09:34:32Z", GoVersion:"go1.20.8", Compiler:"gc", Platform:"linux/amd64"} # kubectl version Client Version: v1.28.2 Kustomize Version: v5.0.4-0.20230601165947-6ce0bf390ce3 The connection to the server localhost:8080 was refused - did you specify the right host or port? # kubelet --version Kubernetes v1.28.2
说明: kubelet现在每隔几秒就会重启,它陷入了一个等待 kubeadm 指令的死循环, 这是符合预期的。 接下来需要在主节点执行kubeadm init,初始化k8s集群
2. 初始化k8s集群 在主节点执行kubeadm init 1 2 3 4 kubeadm init --apiserver-advertise-address 192.168.52.91 \ --image-repository registry.aliyuncs.com/google_containers \ --kubernetes-version v1.28.2 \ --pod-network-cidr=198.18.0.0/16
参数说明:
执行时间较长,耐心等几分钟。 执行成功后,会打印如下内容,提示你下一步怎么做
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.52.91:6443 --token qtmi2g.1jnqftmkjm72xb75 \ --discovery-token-ca-cert-hash sha256:0b94fe5b0e0405dc3cea832a5d2100ef8f4505196f52f8c7c992504b5b419532
我使用的是root用户,参照上面的提示,只需export环境变量KUBECONFIG,操作如下:
1 export KUBECONFIG=/etc/kubernetes/admin.conf
使环境变量立即生效
此时,kubectl已经可以查到如下pod, 但coredns pod运行不成功。下一步需要在主节点上安装网络插件
1 2 3 4 5 6 7 8 9 kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE kube-system coredns-66f779496c-8ctsc 0/1 Pending 0 3m11s kube-system coredns-66f779496c-hx76v 0/1 Pending 0 3m11s kube-system etcd-k8s-master 1/1 Running 0 3m24s kube-system kube-apiserver-k8s-master 1/1 Running 0 3m24s kube-system kube-controller-manager-k8s-master 1/1 Running 0 3m24s kube-system kube-proxy-89c9k 1/1 Running 0 3m11s kube-system kube-scheduler-k8s-master 1/1 Running 0 3m24s
在主节点安装calico网络插件 安装网络插件,可以选择calico或者flannel,我这里选calico,安装参考官方文档
1 2 3 yum install -y wget wget https://raw.githubusercontent.com/projectcalico/calico/v3.29.1/manifests/tigera-operator.yaml kubectl create -f tigera-operator.yaml
2、Install Calico by creating the necessary custom resource.
1 2 3 wget https://raw.githubusercontent.com/projectcalico/calico/v3.29.1/manifests/custom-resources.yaml 修改custom-resources.yaml, 把cidr改成198.18.0.0/16 kubectl create -f custom-resources.yaml
3、Confirm that all of the pods are running with the following command.
1 watch kubectl get pods -n calico-system
Wait until each pod has the STATUS of Running.
4、Remove the taints on the control plane so that you can schedule pods on it.
1 2 kubectl taint nodes --all node-role.kubernetes.io/control-plane- node/k8s-master untainted
注: 后续如果希望业务容器只调度到工作节点, 需要加上这个污点
5、 Confirm that you now have a node in your cluster with the following command.
1 2 3 kubectl get nodes -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME k8s-master Ready control-plane 5h16m v1.28.2 10.206.216.96 <none> Rocky Linux 9.4 (Blue Onyx) 5.14.0-427.13.1.el9_4.x86_64 containerd://1.7.24
注: 如果是国内用户,会遇到Pod启动失败问题,需要手动从国内镜像站拉取镜像,再改一下tag即可 (国内镜像站: https://docker.aityp.com )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ctr -n k8s.io images pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/apiserver:v3.29.1 ctr -n k8s.io images tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/apiserver:v3.29.1 docker.io/calico/apiserver:v3.29.1 ctr -n k8s.io images pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/cni:v3.29.1 ctr -n k8s.io images tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/cni:v3.29.1 docker.io/calico/cni:v3.29.1 ctr -n k8s.io images pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/csi:v3.29.1 ctr -n k8s.io images tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/csi:v3.29.1 docker.io/calico/csi:v3.29.1 ctr -n k8s.io images pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/kube-controllers:v3.29.1 ctr -n k8s.io images tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/kube-controllers:v3.29.1 docker.io/calico/kube-controllers:v3.29.1 ctr -n k8s.io images pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/node-driver-registrar:v3.29.1 ctr -n k8s.io images tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/node-driver-registrar:v3.29.1 docker.io/calico/node-driver-registrar:v3.29.1 ctr -n k8s.io images pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/node:v3.29.1 ctr -n k8s.io images tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/node:v3.29.1 docker.io/calico/node:v3.29.1 ctr -n k8s.io images pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/pod2daemon-flexvol:v3.29.1 ctr -n k8s.io images tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/pod2daemon-flexvol:v3.29.1 docker.io/calico/pod2daemon-flexvol:v3.29.1 ctr -n k8s.io images pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/typha:v3.29.1 ctr -n k8s.io images tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/calico/typha:v3.29.1 docker.io/calico/typha:v3.29.1
导入镜像后, 查看calico Pod创建成功
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE calico-apiserver calico-apiserver-5cb44cddc4-tjb85 1/1 Running 0 22m calico-apiserver calico-apiserver-5cb44cddc4-v4nlj 1/1 Running 0 22m calico-system calico-kube-controllers-69d6c7f5d4-tnnn7 1/1 Running 0 107s calico-system calico-node-bwg5x 1/1 Running 0 47s calico-system calico-typha-8cc7f9579-hksgd 1/1 Running 0 107s calico-system csi-node-driver-j4tfr 2/2 Running 0 107s kube-system coredns-66f779496c-5k796 1/1 Running 0 49m kube-system coredns-66f779496c-mxc5j 1/1 Running 0 49m kube-system etcd-k8s-master1 1/1 Running 1 (3m50s ago) 50m kube-system kube-apiserver-k8s-master1 1/1 Running 1 (3m50s ago) 50m kube-system kube-controller-manager-k8s-master1 1/1 Running 1 (3m50s ago) 50m kube-system kube-proxy-gczxm 1/1 Running 1 (3m50s ago) 49m kube-system kube-scheduler-k8s-master1 1/1 Running 1 (3m50s ago) 50m tigera-operator tigera-operator-c7ccbd65-rzt2l 1/1 Running 1 (3m50s ago) 27m
安装calicoctl 参考官方文档: https://docs.tigera.io/calico/latest/operations/calicoctl/install
1 2 3 curl -L https://github.com/projectcalico/calico/releases/download/v3.29.1/calicoctl-linux-amd64 -o calicoctl chmod +x ./calicoctl cp calicoctl /usr/bin/
calicoctl查看节点
1 2 3 4 5 6 7 8 9 10 11 12 # calicoctl node status Calico process is running. IPv4 BGP status No IPv4 peers found. IPv6 BGP status No IPv6 peers found. # calicoctl get nodes NAME k8s-master1
3. 把从节点加入集群 先在Master节点上获取token 1 2 3 kubeadm token list | awk '{print $1}' TOKEN qtmi2g.1jnqftmkjm72xb75
默认token 24小时内过期,如果过期了,可以在主节点上重新创建新token
再从主节点上获取–discovery-token-ca-cert-hash的值 1 2 3 openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | \ openssl dgst -sha256 -hex | sed 's/^.* //' 0b94fe5b0e0405dc3cea832a5d2100ef8f4505196f52f8c7c992504b5b419532
最后, 从节点执行kubeadm join命令,将从节点加入集群: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 kubeadm join --token qtmi2g.1jnqftmkjm72xb75 \ 192.168.52.91:6443 \ --discovery-token-ca-cert-hash sha256:0b94fe5b0e0405dc3cea832a5d2100ef8f4505196f52f8c7c992504b5b419532 [preflight] Running pre-flight checks [WARNING Service-Kubelet]: kubelet service is not enabled, please run 'systemctl enable kubelet.service' [preflight] Reading configuration from the cluster... [preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Starting the kubelet [kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap... This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details. Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
将kubelet设为开机自启动
1 systemctl enable kubelet.service
查看从节点是否加入成功 需要等几分钟,直到所有Pod创建完成 (国内用户需要手动在从节点上下载calico镜像)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE calico-apiserver calico-apiserver-5cb44cddc4-tjb85 1/1 Running 0 50m calico-apiserver calico-apiserver-5cb44cddc4-v4nlj 1/1 Running 0 50m calico-system calico-kube-controllers-69d6c7f5d4-tnnn7 1/1 Running 0 30m calico-system calico-node-bwg5x 1/1 Running 0 29m calico-system calico-node-rtsfd 1/1 Running 0 14m calico-system calico-typha-8cc7f9579-hksgd 1/1 Running 0 30m calico-system csi-node-driver-chs4d 2/2 Running 0 14m calico-system csi-node-driver-j4tfr 2/2 Running 0 30m kube-system coredns-66f779496c-5k796 1/1 Running 0 78m kube-system coredns-66f779496c-mxc5j 1/1 Running 0 78m kube-system etcd-k8s-master1 1/1 Running 1 (32m ago) 78m kube-system kube-apiserver-k8s-master1 1/1 Running 1 (32m ago) 78m kube-system kube-controller-manager-k8s-master1 1/1 Running 1 (32m ago) 78m kube-system kube-proxy-gczxm 1/1 Running 1 (32m ago) 78m kube-system kube-proxy-wfhh7 1/1 Running 0 14m kube-system kube-scheduler-k8s-master1 1/1 Running 1 (32m ago) 78m tigera-operator tigera-operator-c7ccbd65-rzt2l 1/1 Running 1 (32m ago) 56m
可以查到主, 从节点已经Ready
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 # kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master Ready control-plane 5h33m v1.28.2 k8s-node1 Ready <none> 11m v1.28.2 k8s-node2 Ready <none> 11m v1.28.2 # calicoctl node status Calico process is running. IPv4 BGP status +----------------+-------------------+-------+----------+-------------+ | PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO | +----------------+-------------------+-------+----------+-------------+ | 192.168.52.101 | node-to-node mesh | up | 14:38:07 | Established | +----------------+-------------------+-------+----------+-------------+ IPv6 BGP status No IPv6 peers found. # calicoctl get nodes NAME k8s-master1 k8s-slave1
4. 简单测试一主一从集群,在集群上部署Nginx 创建Nginx deployment(nginx-deployment.yaml), 设置副本数为2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: selector: matchLabels: app: nginx replicas: 3 # 副本数设置为3,假设集群中有三个节点,每个节点上会尝试运行一个Nginx实例(但k8s会根据资源情况和调度策略来实际分配) template: metadata: labels: app: nginx spec: containers: - name: nginx image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/nginx:1.19-alpine ports: - containerPort: 80
创建Service(nginx-service.yaml), NodePort暴露服务
1 2 3 4 5 6 7 8 9 10 11 12 13 apiVersion: v1 kind: Service metadata: name: nginx-service spec: type: NodePort selector: app: nginx ports: - protocol: TCP port: 80 targetPort: 80 nodePort: 30080 # 可以指定具体的NodePort,确保端口不冲突且在范围内(30000-32767)
应用deployment, Service
1 2 kubectl apply -f nginx-deployment.yaml kubectl apply -f nginx-service.yaml
查看Pod, Nginx pod只调度到了工作节点上
1 2 3 4 5 6 7 8 # kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-deployment-645d5cfc8b-h8qnr 1/1 Running 0 14s 198.18.0.72 k8s-slave1 <none> <none> nginx-deployment-645d5cfc8b-hdn8k 1/1 Running 0 14s 198.18.0.71 k8s-slave1 <none> <none> nginx-deployment-645d5cfc8b-lkjms 1/1 Running 0 14s 198.18.0.73 k8s-slave1 <none> <none> kubectl get svc | grep nginx nginx-service NodePort 10.105.69.177 <none> 80:30080/TCP 49s
通过任意节点请求Nginx, 返回200 OK
1 2 3 4 # curl k8s-master1:30080 -i HTTP/1.1 200 OK # curl k8s-slave1:30080 -i HTTP/1.1 200 OK
删除deployment和service
1 2 3 4 [root@k8s-master ~]# kubectl delete deploy nginx-deployment deployment.apps "nginx-deployment" deleted # kubectl delete service nginx-service service "nginx-service" deleted
二、 配置负载均衡 准备两个节点用于负载均衡, 以及一个Virtual IP, 某个节点发生故障时, Virtual IP可以漂移到另一个节点, 从而实现高可用
1 2 3 192.168.52.80 HAProxy 192.168.52.81 HAProxy 192.168.52.88 www.petertest.com Virtual IP
关闭SELinux和firewalld
1 2 3 4 systemctl stop firewalld systemctl disable firewalld setenforce 0 sed --follow-symlinks -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
安装keepalived和HAproxy 1 yum install keepalived haproxy psmisc -y
配置HAproxy vi /etc/haproxy/haproxy.cfg
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 global log /dev/log local0 warning chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon stats socket /var/lib/haproxy/stats defaults log global option httplog option dontlognull timeout connect 5000 timeout client 50000 timeout server 50000 frontend kube-apiserver bind *:6443 mode tcp option tcplog default_backend kube-apiserver backend kube-apiserver mode tcp option tcplog option tcp-check balance roundrobin default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100 server kube-apiserver-1 192.168.52.91:6443 check # Replace the IP address with your own.
重启HAProxy, 设置开机自动运行
1 2 systemctl restart haproxy systemctl enable haproxy
测试一下HAProxy
1 2 3 4 curl localhost:6443 curl: (52) Empty reply from server tcpdump dst port 6443 22:51:02.055968 IP 192.168.52.80.41304 > k8s-master1.sun-sr-https: Flags [S], seq 1465862176, win 32120, options [mss 1460,sackOK,TS val 2222524931 ecr 0,nop,wscale 7], length 0
配置keepalived 1 2 3 192.168.52.80 k8s-lb1 HAProxy 192.168.52.81 k8s-lb2 HAProxy 192.168.52.88 www.petertest.com Virtual IP
k8s-lb1配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 global_defs { router_id LVS_DEVEL # 每个keepalived实例应该有一个唯一的router_id } vrrp_script chk_haproxy { script "killall -0 haproxy" # 使用killall命令检查haproxy是否存活 interval 2 # 检查间隔为2秒 weight 2 # 如果脚本失败,优先级减少2 } vrrp_instance haproxy-vip { state MASTER # 对于主服务器应设置为MASTER,对于备用服务器设置为BACKUP priority 100 # 主服务器的优先级应高于备用服务器 interface ens160 # 绑定的网络接口名称,请根据实际情况调整 virtual_router_id 60 # 虚拟路由ID,必须在主备服务器上保持一致 advert_int 1 # 广告间隔时间 authentication { # 认证信息,用于主备服务器间通信 auth_type PASS auth_pass 1111 # 这里的密码需要在主备服务器上保持一致 } unicast_src_ip 192.168.52.80 # 本机IP地址 unicast_peer { # 单播对等体列表,列出所有参与VRRP组的其他节点 192.168.52.81 # 备用服务器的IP地址 } virtual_ipaddress { 192.168.52.88/24 # 虚拟IP地址及其子网掩码 } track_script { chk_haproxy # 引用之前定义的健康检查脚本 } }
重启keepalived, 设置自启动
1 2 systemctl restart keepalived systemctl enable keepalived
k8s-lb2也配置keepalived, 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 global_defs { router_id LVS_DEVEL_BACKUP # 这个ID需要和主服务器的router_id区分开来 } vrrp_script chk_haproxy { script "killall -0 haproxy" # 检查haproxy是否存活 interval 2 # 每2秒执行一次检查 weight 2 # 如果脚本失败,优先级减少2 } vrrp_instance haproxy-vip { state BACKUP # 设置为BACKUP状态 priority 99 # 优先级要比主服务器低,例如设置为99 interface ens160 # 绑定的网络接口,根据实际情况修改 virtual_router_id 60 # 虚拟路由ID,必须与主服务器保持一致 advert_int 1 # 广告间隔时间 authentication { auth_type PASS auth_pass 1111 # 认证密码需与主服务器相同 } unicast_src_ip 192.168.52.81 # 当前服务器的IP地址 unicast_peer { 192.168.52.80 # 主服务器的IP地址 } virtual_ipaddress { 192.168.52.88/24 # 虚拟IP地址及其子网掩码,需与主服务器保持一致 } track_script { chk_haproxy # 引用健康检查脚本 } }
验证高可用 curl测试VIP, 同时可以在某个LB实例上通过ip addr查到VIP
1 2 3 4 5 6 7 8 9 10 11 12 curl 192.168.52.88:6443 curl: (52) Empty reply from server ip addr # ip addr 2: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 00:0c:29:4f:99:01 brd ff:ff:ff:ff:ff:ff altname enp3s0 inet 192.168.52.80/24 brd 192.168.52.255 scope global noprefixroute ens160 valid_lft forever preferred_lft forever inet 192.168.52.88/24 scope global secondary ens160 valid_lft forever preferred_lft forever
测试高可用, 任意关机一台LB, VIP仍能访问, 且成功漂移到另一台LB
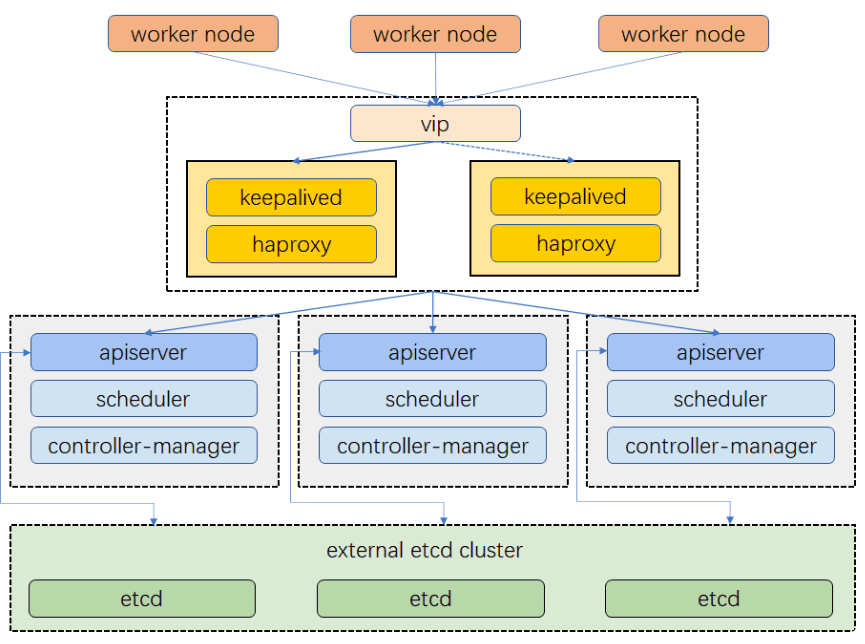
三、搭建高可用集群(三主三从两LB) 重置之前的k8s节点 在主节点执行如下命令, 把从节点移出集群
1 kubectl delete node k8s-slave1
在从节点执行, 重置从节点
1 2 3 systemctl stop kubelet kubeadm reset rm -rf /etc/kubernetes/*
重置主节点
1 2 kubeadm reset rm -rf $HOME/.kube
用VIP重新初始化主节点 1 2 3 4 kubeadm init --control-plane-endpoint="www.petertest.com:6443" --upload-certs \ --image-repository registry.aliyuncs.com/google_containers \ --kubernetes-version v1.28.2 \ --pod-network-cidr=198.18.0.0/16
执行后,输出提示, 它告诉你如何加入其他主节点和工作节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of the control-plane node running the following command on each as root: kubeadm join www.petertest.com:6443 --token oa0iql.m7pbqe76ox30cmj2 \ --discovery-token-ca-cert-hash sha256:f68a231370853f52c1894f34b86e32069f2748be8f54d67f661d59d6e11a8fc8 \ --control-plane --certificate-key 548e38fad35f8f97ff066decd6a779a037e30cf0490e2facd78cd6dbb14a7371 Please note that the certificate-key gives access to cluster sensitive data, keep it secret! As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use "kubeadm init phase upload-certs --upload-certs" to reload certs afterward. Then you can join any number of worker nodes by running the following on each as root: kubeadm join www.petertest.com:6443 --token oa0iql.m7pbqe76ox30cmj2 \ --discovery-token-ca-cert-hash sha256:f68a231370853f52c1894f34b86e32069f2748be8f54d67f661d59d6e11a8fc8
测试VIP, 返回200 OK
1 2 curl https://www.petertest.com:6443/healthz -k ok
注: 国内用户需手动下载calico镜像
加入其余两个主节点 1 2 3 4 5 6 7 8 9 kubeadm join www.petertest.com:6443 --token oa0iql.m7pbqe76ox30cmj2 \ --discovery-token-ca-cert-hash sha256:f68a231370853f52c1894f34b86e32069f2748be8f54d67f661d59d6e11a8fc8 \ --control-plane --certificate-key 548e38fad35f8f97ff066decd6a779a037e30cf0490e2facd78cd6dbb14a7371 mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config systemctl enable kubelet.service
注: 国内用户需手动下载并导入calico镜像
加入其余两个从节点 1 2 3 4 kubeadm join www.petertest.com:6443 --token oa0iql.m7pbqe76ox30cmj2 \ --discovery-token-ca-cert-hash sha256:f68a231370853f52c1894f34b86e32069f2748be8f54d67f661d59d6e11a8fc8 systemctl enable kubelet.service
注: 国内用户需手动下载并导入calico镜像
测试集群 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 kubectl get nodes [root@k8s-master1 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master1 Ready control-plane 72m v1.28.2 k8s-master2 Ready control-plane 44m v1.28.2 k8s-master3 Ready control-plane 22m v1.28.2 k8s-slave1 Ready <none> 11m v1.28.2 k8s-slave2 Ready <none> 5m46s v1.28.2 k8s-slave3 Ready <none> 5m44s v1.28.2 # kubectl get pods -A -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES calico-apiserver calico-apiserver-74966f94d7-cjjjp 1/1 Running 2 (30m ago) 68m 198.18.159.142 k8s-master1 <none> <none> calico-apiserver calico-apiserver-74966f94d7-xxvvh 1/1 Running 2 (30m ago) 68m 198.18.159.143 k8s-master1 <none> <none> calico-system calico-kube-controllers-6c7d459d66-9t72c 1/1 Running 2 (30m ago) 68m 198.18.159.146 k8s-master1 <none> <none> calico-system calico-node-59ffd 1/1 Running 0 42m 192.168.52.92 k8s-master2 <none> <none> calico-system calico-node-bphnr 1/1 Running 1 15m 192.168.52.101 k8s-slave1 <none> <none> calico-system calico-node-jk4q8 1/1 Running 2 (30m ago) 68m 192.168.52.91 k8s-master1 <none> <none> calico-system calico-node-pnjhc 1/1 Running 0 21m 192.168.52.93 k8s-master3 <none> <none> calico-system calico-node-x4llg 1/1 Running 0 4m18s 192.168.52.103 k8s-slave3 <none> <none> calico-system calico-node-x7jfv 1/1 Running 0 4m20s 192.168.52.102 k8s-slave2 <none> <none> calico-system calico-typha-77686bcb79-nxpgq 1/1 Running 0 4m17s 192.168.52.103 k8s-slave3 <none> <none> calico-system calico-typha-77686bcb79-ql94f 1/1 Running 0 21m 192.168.52.93 k8s-master3 <none> <none> calico-system calico-typha-77686bcb79-xtqlg 1/1 Running 2 (30m ago) 68m 192.168.52.91 k8s-master1 <none> <none> calico-system csi-node-driver-25nhw 2/2 Running 4 (30m ago) 68m 198.18.159.147 k8s-master1 <none> <none> calico-system csi-node-driver-28xwt 2/2 Running 2 15m 198.18.0.64 k8s-slave1 <none> <none> calico-system csi-node-driver-4hr97 2/2 Running 0 4m18s 198.18.158.193 k8s-slave3 <none> <none> calico-system csi-node-driver-dwcd8 2/2 Running 0 21m 198.18.135.193 k8s-master3 <none> <none> calico-system csi-node-driver-fspfc 2/2 Running 0 42m 198.18.224.1 k8s-master2 <none> <none> calico-system csi-node-driver-kk92q 2/2 Running 0 4m20s 198.18.92.1 k8s-slave2 <none> <none> kube-system coredns-66f779496c-5lx42 1/1 Running 2 (30m ago) 70m 198.18.159.145 k8s-master1 <none> <none> kube-system coredns-66f779496c-pvx2r 1/1 Running 2 (30m ago) 70m 198.18.159.144 k8s-master1 <none> <none> kube-system etcd-k8s-master1 1/1 Running 7 (30m ago) 70m 192.168.52.91 k8s-master1 <none> <none> kube-system etcd-k8s-master2 1/1 Running 0 42m 192.168.52.92 k8s-master2 <none> <none> kube-system etcd-k8s-master3 1/1 Running 0 21m 192.168.52.93 k8s-master3 <none> <none> kube-system kube-apiserver-k8s-master1 1/1 Running 7 (30m ago) 70m 192.168.52.91 k8s-master1 <none> <none> kube-system kube-apiserver-k8s-master2 1/1 Running 2 (29m ago) 42m 192.168.52.92 k8s-master2 <none> <none> kube-system kube-apiserver-k8s-master3 1/1 Running 0 21m 192.168.52.93 k8s-master3 <none> <none> kube-system kube-controller-manager-k8s-master1 1/1 Running 8 (30m ago) 70m 192.168.52.91 k8s-master1 <none> <none> kube-system kube-controller-manager-k8s-master2 1/1 Running 2 (29m ago) 42m 192.168.52.92 k8s-master2 <none> <none> kube-system kube-controller-manager-k8s-master3 1/1 Running 0 21m 192.168.52.93 k8s-master3 <none> <none> kube-system kube-proxy-58pvn 1/1 Running 0 42m 192.168.52.92 k8s-master2 <none> <none> kube-system kube-proxy-7jwg6 1/1 Running 0 4m20s 192.168.52.102 k8s-slave2 <none> <none> kube-system kube-proxy-7x4wf 1/1 Running 0 4m18s 192.168.52.103 k8s-slave3 <none> <none> kube-system kube-proxy-8khss 1/1 Running 0 21m 192.168.52.93 k8s-master3 <none> <none> kube-system kube-proxy-ctjcc 1/1 Running 2 (30m ago) 70m 192.168.52.91 k8s-master1 <none> <none> kube-system kube-proxy-m2g7p 1/1 Running 1 15m 192.168.52.101 k8s-slave1 <none> <none> kube-system kube-scheduler-k8s-master1 1/1 Running 7 (30m ago) 70m 192.168.52.91 k8s-master1 <none> <none> kube-system kube-scheduler-k8s-master2 1/1 Running 0 42m 192.168.52.92 k8s-master2 <none> <none> kube-system kube-scheduler-k8s-master3 1/1 Running 0 21m 192.168.52.93 k8s-master3 <none> <none> tigera-operator tigera-operator-c7ccbd65-zgdv6 1/1 Running 3 (30m ago) 68m 192.168.52.91 k8s-master1 <none> <none> # calicoctl node status Calico process is running. IPv4 BGP status +----------------+-------------------+-------+----------+-------------+ | PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO | +----------------+-------------------+-------+----------+-------------+ | 192.168.52.92 | node-to-node mesh | up | 16:10:22 | Established | | 192.168.52.93 | node-to-node mesh | up | 16:19:50 | Established | | 192.168.52.101 | node-to-node mesh | up | 16:30:01 | Established | | 192.168.52.103 | node-to-node mesh | up | 16:38:33 | Established | | 192.168.52.102 | node-to-node mesh | up | 16:38:35 | Established | +----------------+-------------------+-------+----------+-------------+ IPv6 BGP status No IPv6 peers found. [root@k8s-master1 ~]# calicoctl get nodes NAME k8s-master1 k8s-master2 k8s-master3 k8s-slave1 k8s-slave2 k8s-slave3
安装etcdctl, 检查etcd状态 我在安装集群的时候误将k8s-slave1作为主节点加入, 所以通过etcdctl将slave1节点移除. etcdctl安装和使用方法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 wget https://github.com/etcd-io/etcd/releases/download/v3.5.9/etcd-v3.5.9-linux-amd64.tar.gz tar zxvf etcd-v3.5.9-linux-amd64.tar.gz cp etcd-v3.5.9-linux-amd64/etcdctl /usr/local/bin/ # ETCDCTL_API=3 etcdctl \ --cert /etc/kubernetes/pki/etcd/peer.crt \ --key /etc/kubernetes/pki/etcd/peer.key \ --cacert /etc/kubernetes/pki/etcd/ca.crt \ --endpoints=https://192.168.52.91:2379,https://192.168.52.92:2379,https://192.168.52.93:2379 endpoint status --cluster -w table {"level":"warn","ts":"2025-03-19T22:20:14.844504+0800","logger":"etcd-client","caller":"v3@v3.5.9/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"etcd-endpoints://0xc000338c40/192.168.52.91:2379","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = latest balancer error: last connection error: connection error: desc = \"transport: Error while dialing dial tcp 192.168.52.101:2379: connect: connection refused\""} Failed to get the status of endpoint https://192.168.52.101:2379 (context deadline exceeded) +----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://192.168.52.91:2379 | d7096f0da355cc9 | 3.5.9 | 12 MB | false | false | 9 | 31702 | 31702 | | | https://192.168.52.92:2379 | 1f466381ed3a930e | 3.5.9 | 12 MB | true | false | 9 | 31702 | 31702 | | | https://192.168.52.93:2379 | 392021bed5f5dcb2 | 3.5.9 | 12 MB | false | false | 9 | 31702 | 31702 | | +----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ # ETCDCTL_API=3 etcdctl --endpoints=https://192.168.52.91:2379 \ --cert=/etc/kubernetes/pki/etcd/peer.crt \ --key=/etc/kubernetes/pki/etcd/peer.key \ --cacert=/etc/kubernetes/pki/etcd/ca.crt member list d7096f0da355cc9, started, k8s-master1, https://192.168.52.91:2380, https://192.168.52.91:2379, false 1f466381ed3a930e, started, k8s-master2, https://192.168.52.92:2380, https://192.168.52.92:2379, false 392021bed5f5dcb2, started, k8s-master3, https://192.168.52.93:2380, https://192.168.52.93:2379, false b863ac19f9f92e30, started, k8s-slave1, https://192.168.52.101:2380, https://192.168.52.101:2379, false 移除slave1节点 ETCDCTL_API=3 etcdctl --endpoints=https://192.168.52.91:2379 \ --cert=/etc/kubernetes/pki/etcd/peer.crt \ --key=/etc/kubernetes/pki/etcd/peer.key \ --cacert=/etc/kubernetes/pki/etcd/ca.crt member remove b863ac19f9f92e30
高可用配置 修改coredns, calico-apiserver, tigera-operator的deployment, 副本设置为3个以上, 分布在多个节点
测试高可用 部署Nginx Pod(NodePort类型, 副本6, NodePort: 30080)
1 2 3 4 5 6 7 8 # kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-deployment-645d5cfc8b-76xqv 1/1 Running 1 (40m ago) 22h 198.18.0.76 k8s-slave1 <none> <none> nginx-deployment-645d5cfc8b-8mlhv 1/1 Running 1 (40m ago) 22h 198.18.0.73 k8s-slave1 <none> <none> nginx-deployment-645d5cfc8b-bsr2n 1/1 Running 1 (40m ago) 22h 198.18.92.12 k8s-slave2 <none> <none> nginx-deployment-645d5cfc8b-gkk52 1/1 Running 1 (40m ago) 22h 198.18.92.11 k8s-slave2 <none> <none> nginx-deployment-645d5cfc8b-kwr8j 1/1 Running 1 (40m ago) 22h 198.18.158.206 k8s-slave3 <none> <none> nginx-deployment-645d5cfc8b-ms5ms 1/1 Running 1 (40m ago) 22h 198.18.158.208 k8s-slave3 <none> <none>
修改两台LB的Haproxy配置文件(/etc/haproxy/haproxy.cfg), 结尾添加如下内容:
1 2 3 4 5 6 7 8 9 frontend http-in bind *:80 default_backend nginx_servers backend nginx_servers balance roundrobin server node1 k8s-slave1:30080 check server node2 k8s-slave2:30080 check server node3 k8s-slave3:30080 check
重启haproxy
1 systemctl restart haproxy
测试: down任意一个节点, 仍能通过VIP访问Nginx服务, 6443端口正常工作
1 2 3 4 # curl 192.168.52.88 200 OK curl https://192.168.52.88:6443/healthz -k ok
到此, 高可用集群搭建完成
参考 https://kubesphere.io/zh/docs/v3.4/installing-on-linux/high-availability-configurations/set-up-ha-cluster-using-keepalived-haproxy/