前言
链表在Redis中的应用非常广泛,链表是列表键的底层实现之一,发布订阅,慢查询,监视器等功能也用到了链表。
以下给出Redis中链表相关的一些思考问题,通过源码分析,给出问题的答案,掌握链表的底层实现原理和设计思路。
源码版本:Redis 6.0.10
问题思考
C语言中如何设计一个通用的泛型链表?
链表和链表节点的实现
以REDIS 6.0.10源码为例,链表的实现参考adlist.h, adlist.c
链表节点通过listNode结构体实现,定义如下:
1
2
3
4
5
| typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
|
可以看出这是一个双向链表,value存储节点值,其类型为void *
节点值的类型为void *,这样设计有什么好处?
节点值设置void *类型,目的是实现一个通用的泛型链表,提高代码复用性。(类似C++的STL容器,多态思想)
考虑实际应用场景中,链表节点值的类型可以是int, float, double等基本类型, 或者是自定义结构体类型,如果简单将value定义为某个具体类型,就只能为每个节点类型定义一个listNodeXX的结构体,同时需额外为每个节点类型新增一套增、删、改、查的API,实现非常繁琐,如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| typedef struct listNodeInt {
struct listNode *prev;
struct listNode *next;
int value;
} listNodeInt;
typedef struct listNodeDouble {
struct listNode *prev;
struct listNode *next;
double value;
} listNodeDouble;
list *listAddNodeHeadInt(list *list, int value);
list *listAddNodeHeadDouble(list *list, double value);
|
可以看出,这种实现方式的问题在于代码重复度过高,难以维护,且扩展性差,每支持一个新的节点类型都要新增代码,这显然是不能接受的。所以节点值类型要设计为void *
仅使用多个listNode也能组成链表,为什么还要额外用一个list结构去持有链表, 这样设计有什么好处?
Redis中额外使用list结构,用于持有链表,简化操作。list结构体定义如下:
1
2
3
4
5
6
7
8
| typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
|
head, tail用于记录表头指针和表尾指针,好处是获取表头节点或表尾节点的时间复杂度为O(1)
len类型用于记录链表长度, 好处是获取链表节点总数的时间复杂度为O(1)
dup, free, match成员用于实现多态链表,对于不同类型的节点,挂接不同的函数钩子,设置特定的复制、释放、比较操作。
- dup函数用于复制节点值
- free函数用于释放节点值
- match函数用于比较两个节点值是否相等
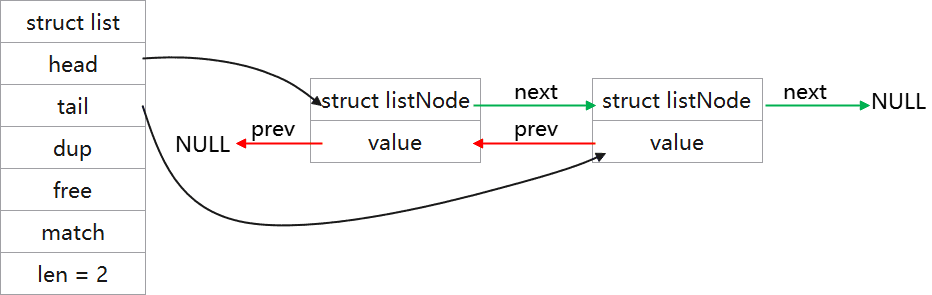
举例:一个长度为2的双向链表示意图:
![]()
为什么用双向链表,不用单链表?
双向链表相较于单链表,有如下优点:
- 支持双向查找节点,且查找给定节点的前驱节点的时间复杂度为O(1)
- 尾部插入节点快,时间复杂度为O(1)
双向链表API实现分析
链表创建
调用listCreate,创建一个空的双向链表,时间复杂度O(1)
1
2
3
4
5
6
7
8
9
10
11
| list *listCreate(void) {
struct list *list;
if ((list = zmalloc(sizeof(*list))) == NULL)
return NULL;
list->head = list->tail = NULL;
list->len = 0;
list->dup = NULL;
list->free = NULL;
list->match = NULL;
return list;
}
|
链表销毁
调用listRelease,释放链表,时间复杂度O(N),N为链表长度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| void listRelease(list *list) {
listEmpty(list);
zfree(list);
}
void listEmpty(list *list) {
unsigned long len;
listNode *current, *next;
current = list->head;
len = list->len;
while(len--) {
next = current->next;
if (list->free) list->free(current->value);
zfree(current);
current = next;
}
list->head = list->tail = NULL;
list->len = 0;
}
|
头部插入节点
调用listAddNodeHead,在链表头部插入节点,时间复杂度O(1)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| list *listAddNodeHead(list *list, void *value) {
listNode *node;
if ((node = zmalloc(sizeof(*node))) == NULL)
return NULL;
node->value = value;
if (list->len == 0) {
list->head = list->tail = node;
node->prev = node->next = NULL;
} else {
node->prev = NULL;
node->next = list->head;
list->head->prev = node;
list->head = node;
}
list->len++;
return list;
}
|
尾部插入节点
调用listAddNodeTail, 在链表尾部插入节点,时间复杂度O(1)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| list *listAddNodeTail(list *list, void *value) {
listNode *node;
if ((node = zmalloc(sizeof(*node))) == NULL)
return NULL;
node->value = value;
if (list->len == 0) {
list->head = list->tail = node;
node->prev = node->next = NULL;
} else {
node->prev = list->tail;
node->next = NULL;
list->tail->next = node;
list->tail = node;
}
list->len++;
return list;
}
|
指定位置前后插入节点
调用listInsertNode,在指定位置之前或之后插入节点,时间复杂度O(1)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| list *listInsertNode(list *list, listNode *old_node, void *value, int after) {
listNode *node;
if ((node = zmalloc(sizeof(*node))) == NULL)
return NULL;
node->value = value;
if (after) {
node->prev = old_node;
node->next = old_node->next;
if (list->tail == old_node) {
list->tail = node;
}
} else {
node->next = old_node;
node->prev = old_node->prev;
if (list->head == old_node) {
list->head = node;
}
}
if (node->prev != NULL) {
node->prev->next = node;
}
if (node->next != NULL) {
node->next->prev = node;
}
list->len++;
return list;
}
|
after等于1时,在给定old_node节点之后插入,否则在给定节点前插入。
删除指定节点
调用listDelNode, 删除指定节点,时间复杂度为O(1)
1
2
3
4
5
6
7
8
9
10
11
12
13
| void listDelNode(list *list, listNode *node) {
if (node->prev)
node->prev->next = node->next;
else
list->head = node->next;
if (node->next)
node->next->prev = node->prev;
else
list->tail = node->prev;
if (list->free) list->free(node->value);
zfree(node);
list->len--;
}
|
链表迭代器的设计实现
定义struct listIter结构体实现链表的迭代器,支持双向迭代。(类似C++容器的begin()和rbegin()操作)
1
2
3
4
5
6
7
8
|
#define AL_START_HEAD 0
#define AL_START_TAIL 1
typedef struct listIter {
listNode *next;
int direction;
} listIter;
|
通过listGetIterator,创建一个正向/反向迭代器:
1
2
3
4
5
6
7
8
9
10
11
| listIter *listGetIterator(list *list, int direction) {
listIter *iter;
if ((iter = zmalloc(sizeof(*iter))) == NULL) return NULL;
if (direction == AL_START_HEAD)
iter->next = list->head;
else
iter->next = list->tail;
iter->direction = direction;
return iter;
}
|
重置迭代器, 通过listRewind和listRewindTail方法:
1
2
3
4
5
6
7
8
9
| void listRewind(list *list, listIter *li) {
li->next = list->head;
li->direction = AL_START_HEAD;
}
void listRewindTail(list *list, listIter *li) {
li->next = list->tail;
li->direction = AL_START_TAIL;
}
|
通过listNext,访问迭代器中的下一个元素:
1
2
3
4
5
6
7
8
9
10
11
| listNode *listNext(listIter *iter) {
listNode *current = iter->next;
if (current != NULL) {
if (iter->direction == AL_START_HEAD)
iter->next = current->next;
else
iter->next = current->prev;
}
return current;
}
|
查找指定节点
调用listSearchKey,查找指定节点,平均时间复杂度O(N),N为链表长度。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| listNode *listSearchKey(list *list, void *key) {
listIter iter;
listNode *node;
listRewind(list, &iter);
while((node = listNext(&iter)) != NULL) {
if (list->match) {
if (list->match(node->value, key)) {
return node;
}
} else {
if (key == node->value) {
return node;
}
}
}
return NULL;
}
|
复制链表
调用listDup,复制链表,时间复杂度O(N),N为链表长度。
实现技巧分析:通过迭代器隐藏链表内部实现,简化链表遍历操作;通过dup函数指针,统一了不同类型链表节点的复制流程,实现简洁优雅,值得一学。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| list *listDup(list *orig) {
list *copy;
listIter iter;
listNode *node;
if ((copy = listCreate()) == NULL)
return NULL;
copy->dup = orig->dup;
copy->free = orig->free;
copy->match = orig->match;
listRewind(orig, &iter);
while((node = listNext(&iter)) != NULL) {
void *value;
if (copy->dup) {
value = copy->dup(node->value);
if (value == NULL) {
listRelease(copy);
return NULL;
}
} else
value = node->value;
if (listAddNodeTail(copy, value) == NULL) {
listRelease(copy);
return NULL;
}
}
return copy;
}
|
表头节点移动到表尾
通过listRotateHeadToTail,实现表头节点移动到表尾,时间复杂度为O(1)
1
2
3
4
5
6
7
8
9
10
11
12
13
| void listRotateHeadToTail(list *list) {
if (listLength(list) <= 1) return;
listNode *head = list->head;
list->head = head->next;
list->head->prev = NULL;
list->tail->next = head;
head->next = NULL;
head->prev = list->tail;
list->tail = head;
}
|
通过listRotateTailToHead,实现表尾节点移动到表头,时间复杂度为O(1)
1
2
3
4
5
6
7
8
9
10
11
12
13
| void listRotateTailToHead(list *list) {
if (listLength(list) <= 1) return;
listNode *tail = list->tail;
list->tail = tail->prev;
list->tail->next = NULL;
list->head->prev = tail;
tail->prev = NULL;
tail->next = list->head;
list->head = tail;
}
|
参考资料
【1】《Redis设计与实现》 第3章 链表