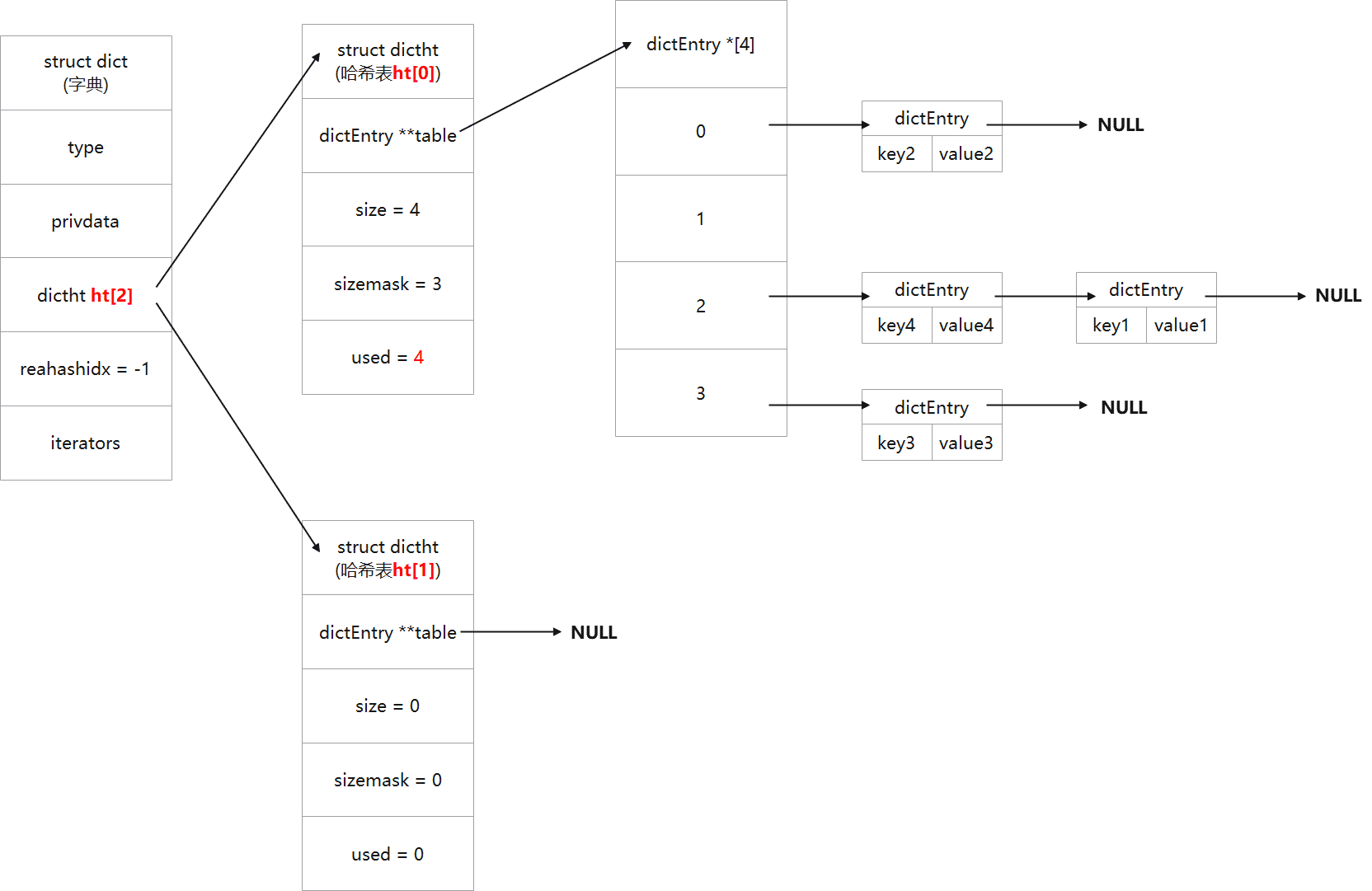
/* If the hash table is empty expand it to the initial size. */ if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
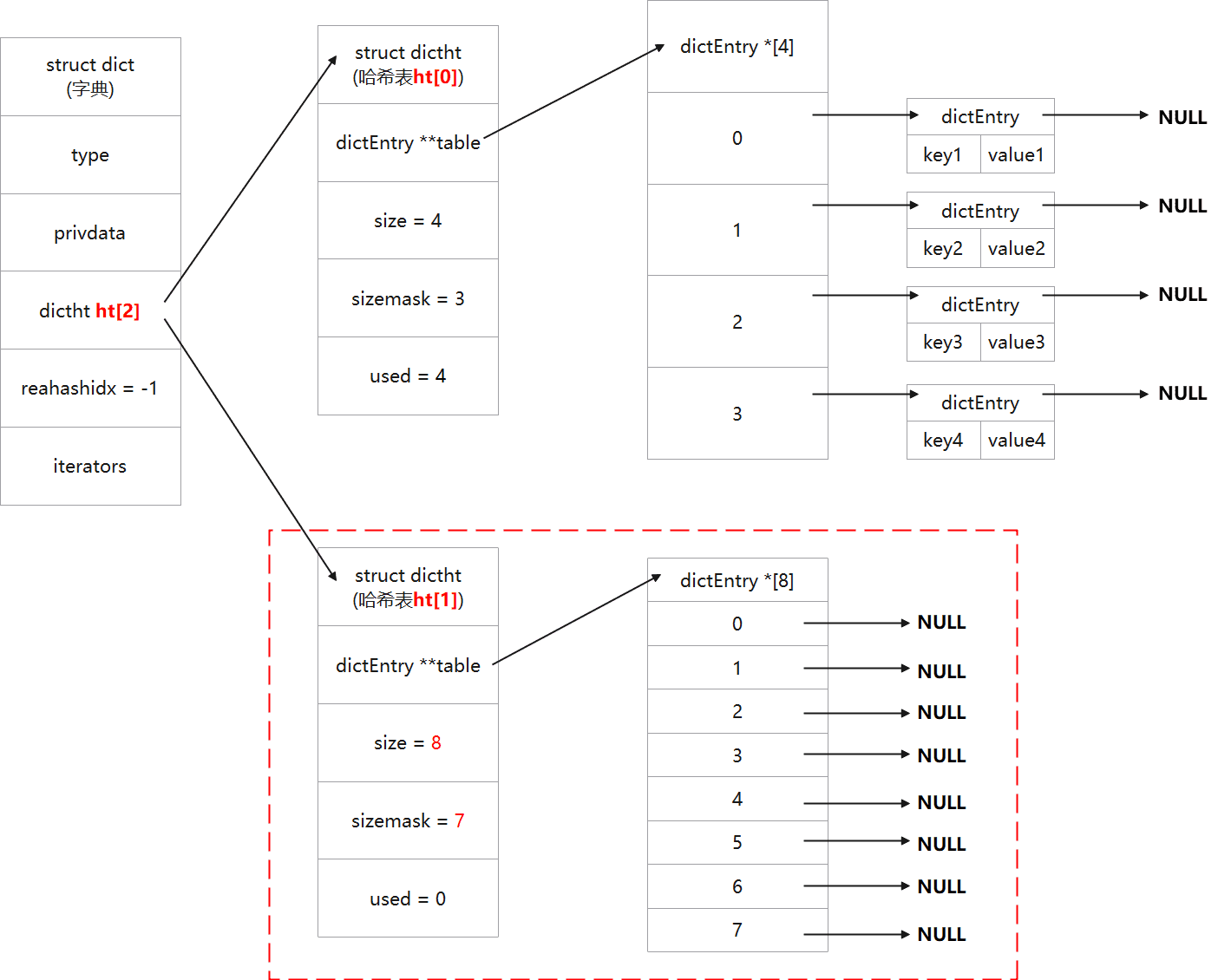
/* If we reached the 1:1 ratio, and we are allowed to resize the hash * table (global setting) or we should avoid it but the ratio between * elements/buckets is over the "safe" threshold, we resize doubling * the number of buckets. */ if (d->ht[0].used >= d->ht[0].size && // 哈希表扩展的条件 (dict_can_resize || d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)) { return dictExpand(d, d->ht[0].used*2); // 扩展操作 } return DICT_OK; }
voidtryResizeHashTables(int dbid) { if (htNeedsResize(server.db[dbid].dict)) dictResize(server.db[dbid].dict); if (htNeedsResize(server.db[dbid].expires)) dictResize(server.db[dbid].expires); }
staticvoid _dictRehashStep(dict *d) { if (d->iterators == 0) dictRehash(d,1); }
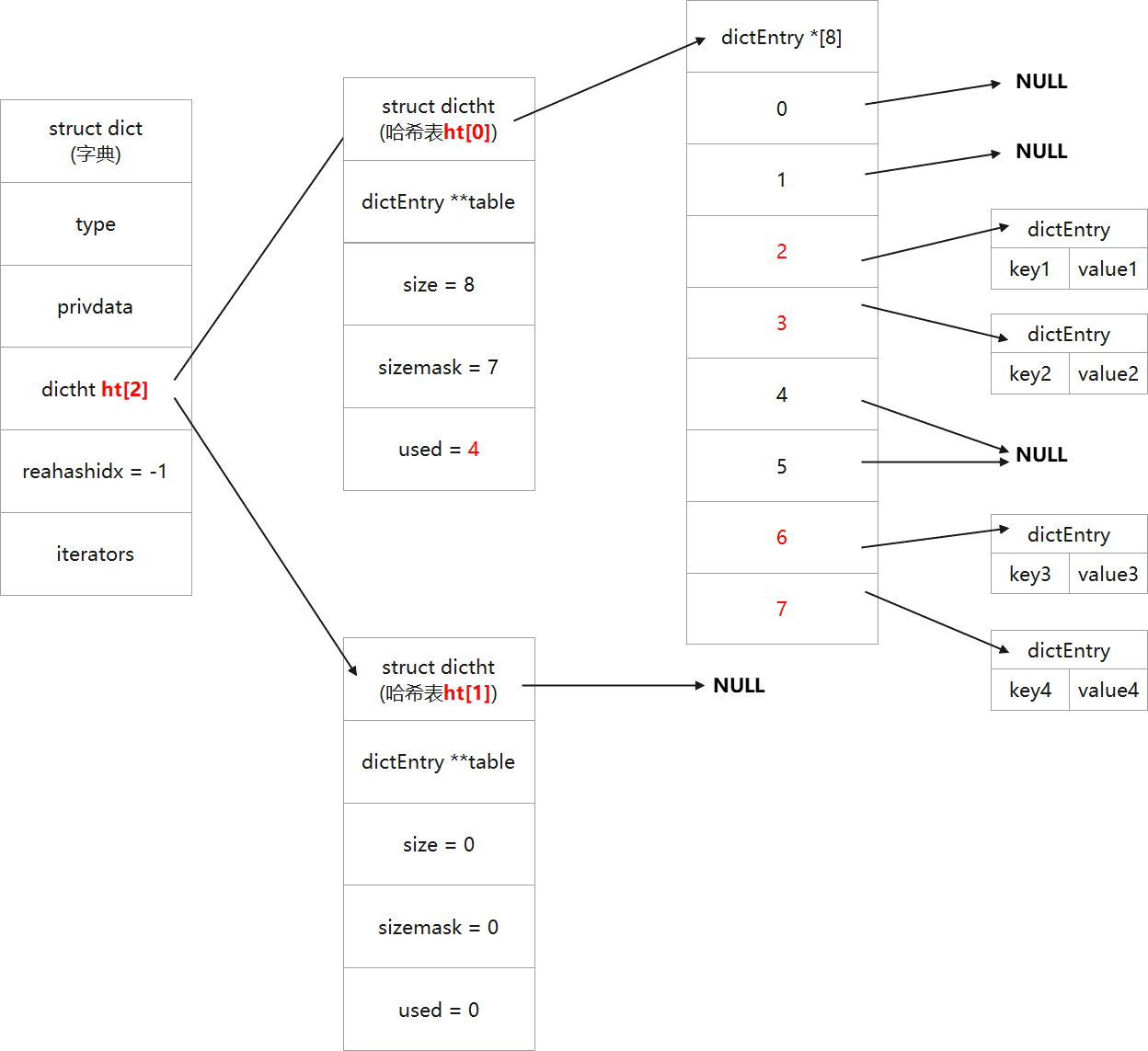
/* Performs N steps of incremental rehashing. Returns 1 if there are still * keys to move from the old to the new hash table, otherwise 0 is returned. * * Note that a rehashing step consists in moving a bucket (that may have more * than one key as we use chaining) from the old to the new hash table, however * since part of the hash table may be composed of empty spaces, it is not * guaranteed that this function will rehash even a single bucket, since it * will visit at max N*10 empty buckets in total, otherwise the amount of * work it does would be unbound and the function may block for a long time. */ intdictRehash(dict *d, int n) { int empty_visits = n*10; /* Max number of empty buckets to visit. */ if (!dictIsRehashing(d)) return0;
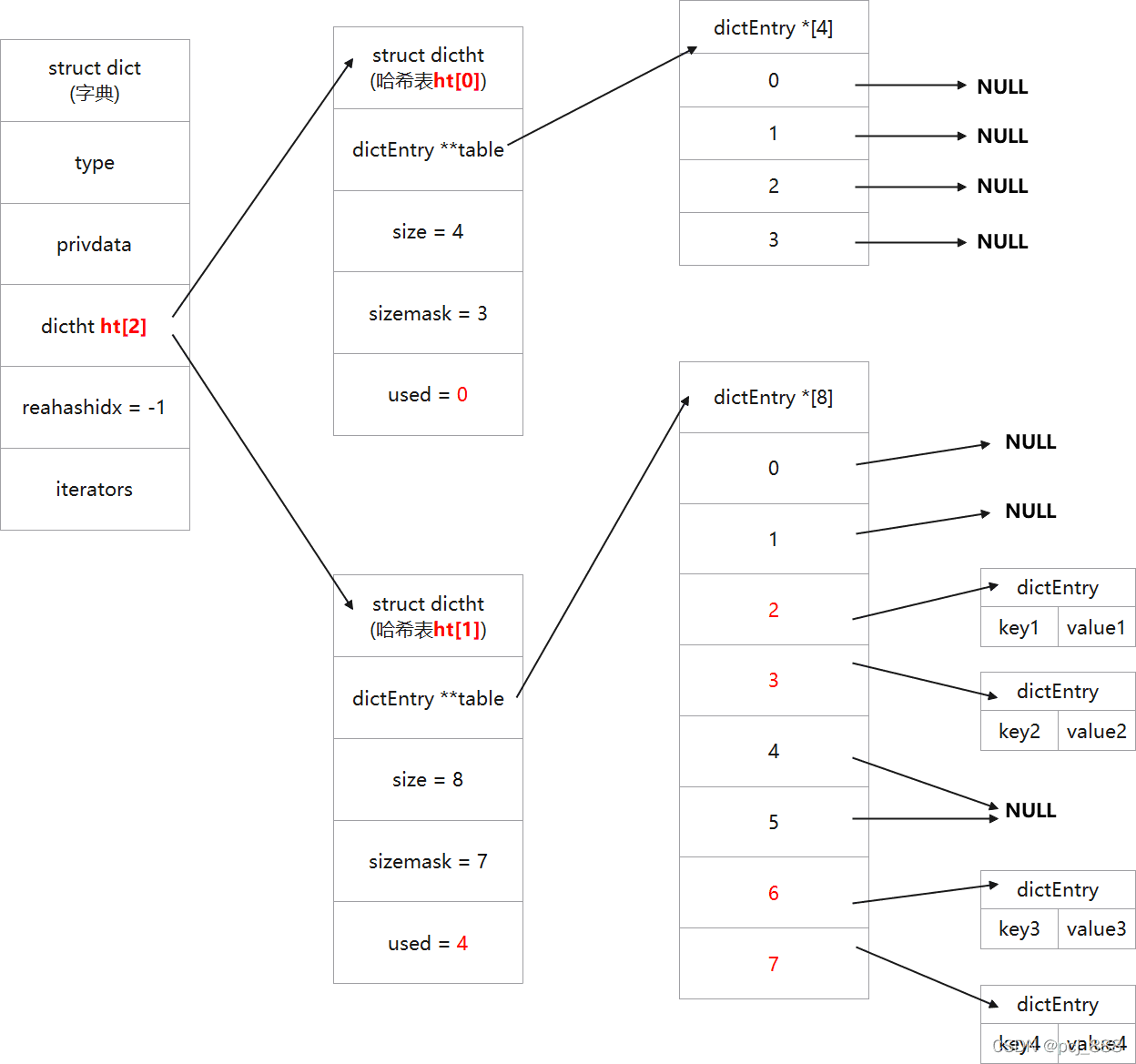
/* Note that rehashidx can't overflow as we are sure there are more * elements because ht[0].used != 0 */ assert(d->ht[0].size > (unsignedlong)d->rehashidx); while(d->ht[0].table[d->rehashidx] == NULL) { d->rehashidx++; if (--empty_visits == 0) return1; } de = d->ht[0].table[d->rehashidx]; /* Move all the keys in this bucket from the old to the new hash HT */ while(de) { uint64_t h;
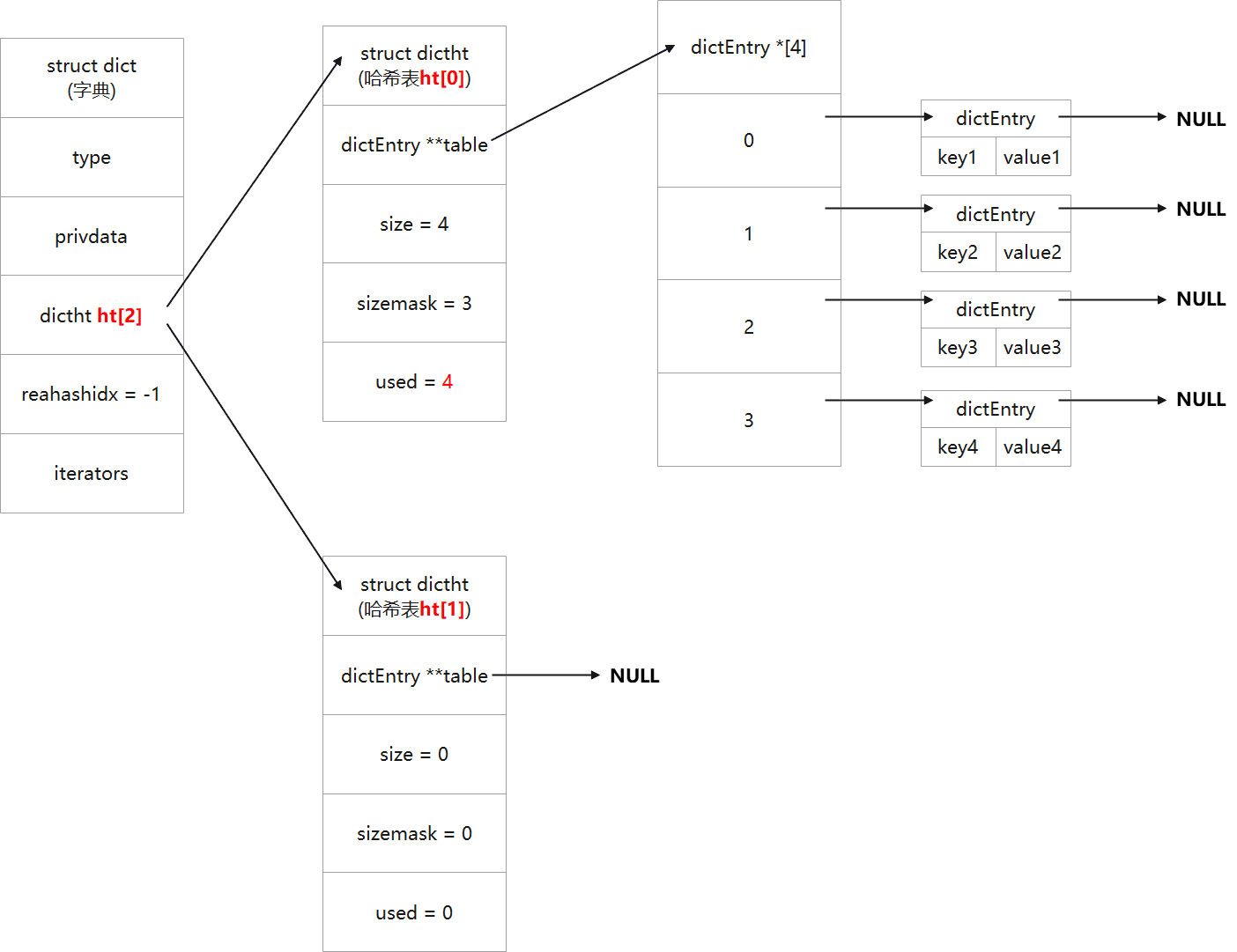
nextde = de->next; /* Get the index in the new hash table */ h = dictHashKey(d, de->key) & d->ht[1].sizemask; de->next = d->ht[1].table[h]; d->ht[1].table[h] = de; d->ht[0].used--; d->ht[1].used++; de = nextde; } d->ht[0].table[d->rehashidx] = NULL; d->rehashidx++; // rehash完成后,将rehashidx计数加1 }
/* Check if we already rehashed the whole table... */ if (d->ht[0].used == 0) { zfree(d->ht[0].table); d->ht[0] = d->ht[1]; _dictReset(&d->ht[1]); d->rehashidx = -1; return0; }
/* Rehash in ms+"delta" milliseconds. The value of "delta" is larger * than 0, and is smaller than 1 in most cases. The exact upper bound * depends on the running time of dictRehash(d,100).*/ intdictRehashMilliseconds(dict *d, int ms) { longlong start = timeInMilliseconds(); int rehashes = 0;
if (dictIsRehashing(d)) _dictRehashStep(d); // 执行一次rehash // 计算哈希索引值 if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1) returnNULL;
/* Allocate the memory and store the new entry. * Insert the element in top, with the assumption that in a database * system it is more likely that recently added entries are accessed * more frequently. */ ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0]; // rehash中,新增的键值对加入ht[1] entry = zmalloc(sizeof(*entry)); entry->next = ht->table[index]; // 头插法,理由是最先插入的节点被频繁访问的可能性越大 ht->table[index] = entry; ht->used++;
/* Set the hash entry fields. */ dictSetKey(d, entry, key); return entry; }
if (dictSize(d) == 0) returnNULL; if (dictIsRehashing(d)) _dictRehashStep(d); if (dictIsRehashing(d)) { do { /* We are sure there are no elements in indexes from 0 * to rehashidx-1 */ h = d->rehashidx + (random() % (d->ht[0].size + d->ht[1].size - d->rehashidx)); he = (h >= d->ht[0].size) ? d->ht[1].table[h - d->ht[0].size] : d->ht[0].table[h]; } while(he == NULL); } else { do { h = random() & d->ht[0].sizemask; he = d->ht[0].table[h]; } while(he == NULL); }
/* Now we found a non empty bucket, but it is a linked * list and we need to get a random element from the list. * The only sane way to do so is counting the elements and * select a random index. */ listlen = 0; orighe = he; while(he) { he = he->next; listlen++; } listele = random() % listlen; he = orighe; while(listele--) he = he->next; return he; }
/* If safe is set to 1 this is a safe iterator, that means, you can call * dictAdd, dictFind, and other functions against the dictionary even while * iterating. Otherwise it is a non safe iterator, and only dictNext() * should be called while iterating. */ typedefstructdictIterator { dict *d; long index; // 当前遍历到的哈希表中的索引值 int table; // 取值只能是0或1 int safe; // 表示这个迭代器是否是安全的,1表示安全,0表示不安全 dictEntry *entry, *nextEntry; // 迭代器指向的当前元素,以及下一个要遍历的元素 /* unsafe iterator fingerprint for misuse detection. */ longlong fingerprint; // 字典的指纹 } dictIterator;